Metode analize časovnih vrst. Povzetek: Časovna vrsta Analiza grafa kaže
Analiza časovnih vrst vam omogoča preučevanje uspešnosti skozi čas. Časovna vrsta je številčna vrednost statističnega kazalnika, urejena v kronološkem vrstnem redu.
Takšni podatki so običajni na različnih področjih človeške dejavnosti: dnevne borzne cene, menjalni tečaji, četrtletni, letni obseg prodaje, proizvodnja itd. Tipična časovna vrsta v meteorologiji, kot je mesečna količina padavin.
Časovne vrste v Excelu
Če beležite vrednosti procesa v določenih intervalih, boste dobili elemente časovne serije. Njihovo variabilnost poskušajo razdeliti na regularne in naključne komponente. Redne spremembe članov serije so praviloma predvidljive.
Naredimo analizo časovnih vrst v Excelu. Primer: trgovska veriga analizira podatke o prodaji blaga iz trgovin, ki se nahajajo v mestih z manj kot 50.000 prebivalci. Obdobje – 2012-2015 Naloga je ugotoviti glavni trend razvoja.
Vnesemo podatke o prodaji v Excelovo tabelo:
Na zavihku »Podatki« kliknite gumb »Analiza podatkov«. Če ni viden, pojdite v meni. "Možnosti Excel" - "Dodatki". Na dnu kliknite »Pojdi« na »Excel Add-ins« in izberite »Analysis Package«.
Podrobno je opisana povezava nastavitve »Analiza podatkov«.
Zahtevani gumb se prikaže na traku.

Na predlaganem seznamu orodij za statistično analizo izberite »Eksponentno glajenje«. Ta metoda izravnave je primerna za naše časovne serije, katerih vrednosti močno nihajo.

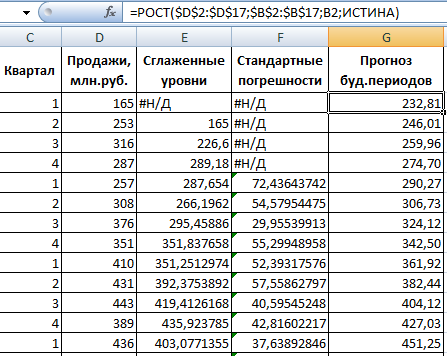
Izpolnite pogovorno okno. Vnosni interval – obseg s prodajnimi vrednostmi. Faktor dušenja – eksponentni koeficient glajenja (privzeto – 0,3). Izhodni obseg – sklic na zgornjo levo celico izhodnega obsega. Program bo sem postavil zglajene nivoje in samostojno določil velikost. Potrdite polja »Izhod grafa«, »Standardne napake«.

Zaprite pogovorno okno s klikom na OK. Rezultati analize:

Za izračun standardnih napak Excel uporablja formulo: =ROOT(SUMVARANGE('dejanski obseg vrednosti'; 'predviden obseg vrednosti')/ 'velikost okna za glajenje'). Na primer =ROOT(SUMVARE(C3:C5,D3:D5)/3).
Napovedovanje časovnih vrst v Excelu
Na podlagi podatkov iz prejšnjega primera naredimo napoved prodaje.
Na graf dodajte trendno črto, ki prikazuje dejanski obseg prodaje izdelkov (desni gumb na grafu – »Dodaj trendno črto«).
Nastavitev parametrov trendne linije:

Izberemo polinomski trend, da zmanjšamo napako modela napovedi.

R2 = 0,9567, kar pomeni: to razmerje pojasnjuje 95,67 % sprememb v prodaji skozi čas.
Enačba trenda je modelna formula za izračun napovedanih vrednosti.

Dobimo dokaj optimističen rezultat:
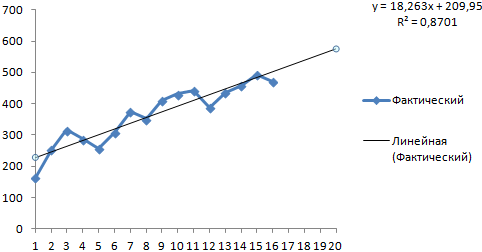
V našem primeru še vedno obstaja eksponentna odvisnost. Zato je pri konstruiranju linearnega trenda več napak in netočnosti.
Za predvidevanje eksponentnih razmerij v Excelu lahko uporabite tudi funkcijo GROWTH.
Za linearno razmerje – TREND.
Pri napovedovanju ne morete uporabiti samo ene metode: obstaja velika verjetnost velikih odstopanj in netočnosti.
Cilji analize časovnih vrst. Pri praktični študiji časovnih vrst, ki temeljijo na ekonomskih podatkih v določenem časovnem obdobju, mora ekonometrik sklepati o lastnostih te serije in verjetnostnem mehanizmu, ki ustvarja to serijo. Najpogosteje so pri preučevanju časovnih vrst postavljeni naslednji cilji:
1. Kratek (stisnjen) opis značilnih lastnosti serije.
2. Izbira statističnega modela, ki opisuje časovno vrsto.
3. Napovedovanje prihodnjih vrednosti na podlagi preteklih opazovanj.
4. Nadzor nad procesom, ki generira časovno vrsto.
V praksi ti in podobni cilji še zdaleč niso vedno in še zdaleč ne povsem uresničljivi. To pogosto ovirajo nezadostna opazovanja zaradi omejenega časa opazovanja. Še pogosteje se statistična struktura časovne vrste skozi čas spreminja.
Faze analize časovnih vrst . Običajno se v praktični analizi časovnih vrst zaporedoma sledijo naslednji stopnji:
1. Grafični prikaz in opis obnašanja začasne rad.
2. Identifikacija in odstranitev rednih časovno odvisnih komponent časovne vrste: trendne, sezonske in ciklične komponente.
3. Izolacija in odstranitev nizko- ali visokofrekvenčnih komponent procesa (filtracija).
4. Študija naključne komponente časovne serije, ki ostane po odstranitvi zgoraj navedenih komponent.
5. Konstrukcija (izbira) matematičnega modela za opis naključne komponente in preverjanje njegove ustreznosti.
6. Napovedovanje prihodnjega razvoja procesa, ki ga predstavlja časovna vrsta.
7. Študij interakcij med različnimi začasne svete.
Obstaja veliko različnih metod za reševanje teh težav. Med njimi so najpogostejši naslednji:
8. Korelacijska analiza, ki omogoča ugotavljanje pomembnih periodičnih odvisnosti in njihovih zamikov (zakasnitev) znotraj enega procesa (avtokorelacija) ali med več procesi (navzkrižna korelacija).
9. Spektralna analiza, ki vam omogoča iskanje periodičnih in kvaziperiodičnih komponent časovne vrste.
10. Glajenje in filtriranje, zasnovano za preoblikovanje časovnih vrst za odstranitev visokofrekvenčnih ali sezonskih nihanj iz njih.
12. Napovedovanje, ki omogoča, da na podlagi izbranega modela obnašanja začasnega rada napovejo njegove vrednosti v prihodnosti.
Trend modeli
najpreprostejši trendni modeli . Tukaj so modeli trendov, ki se najpogosteje uporabljajo pri analizi ekonomskih časovnih vrst, pa tudi na številnih drugih področjih. Prvič, to je preprost linearni model
Kje a 0, a 1– koeficienti modela trendov;
t – čas.
Enota za čas je lahko ura, dan(-i), teden, mesec, četrtletje ali leto. 269 se kljub svoji preprostosti izkaže za uporabnega v številnih aplikacijah v realnem svetu. Če je nelinearna narava trenda očitna, je morda primeren eden od naslednjih modelov:
1. Polinom:
(270)
kjer je stopnja polinoma p pri praktičnih nalogah redko presega 5;
2. Logaritemsko:
Ta model se najpogosteje uporablja za podatke, ki težijo k ohranjanju konstantne stopnje rasti;
3. Logistika:
 (272)
(272)
4. Gompertz
![]() (273), kjer
(273), kjer
Zadnja dva modela proizvajata krivulje trendov v obliki črke S. Ustrezajo procesom s postopno naraščajočimi stopnjami rasti v začetni fazi in postopno upadanjem stopenj rasti na koncu. Potreba po takšnih modelih je posledica nezmožnosti, da se številni ekonomski procesi dolgo časa razvijajo s konstantnimi stopnjami rasti ali po polinomskih modelih zaradi njihove precej hitre rasti (ali upadanja).
Pri napovedovanju se trend uporablja predvsem za dolgoročne napovedi. Natančnost kratkoročnih napovedi, ki temeljijo samo na prilagojeni krivulji trenda, je običajno nezadostna.
Metoda najmanjših kvadratov se najpogosteje uporablja za ocenjevanje in odstranjevanje trendov iz časovnih vrst. Ta metoda je bila podrobneje obravnavana v drugem delu priročnika pri problemih linearne regresijske analize. Vrednosti časovne vrste se obravnavajo kot odziv (odvisna spremenljivka) in čas t– kot dejavnik, ki vpliva na odziv (neodvisna spremenljivka).
Za časovne vrste je značilna medsebojna odvisnost njenih članov (vsaj časovno ne daleč drug od drugega) in to je bistvena razlika od običajne regresijske analize, za katero se predpostavlja, da so vsa opazovanja neodvisna. Vendar pa so ocene trenda pod temi pogoji običajno razumne, če je izbran ustrezen model trenda in če med opazovanji ni velikih odstopanj. Zgoraj omenjene kršitve omejitev regresijske analize ne vplivajo toliko na vrednosti ocen kot na njihove statistične lastnosti. Če torej obstaja pomembna odvisnost med členi časovne vrste, ocene variance na podlagi preostale vsote kvadratov dajo napačne rezultate. Tudi intervali zaupanja za koeficiente modela itd. se izkažejo za nepravilne. V najboljšem primeru se lahko štejejo za zelo približne.
Uvod
To poglavje preučuje problem opisovanja urejenih podatkov, pridobljenih zaporedno (v času). Na splošno se lahko ureditev pojavi ne le v času, ampak tudi v prostoru, na primer premer niti kot funkcija njene dolžine (enodimenzionalni primer), vrednost temperature zraka kot funkcija prostorskih koordinat (tri -dimenzionalni primer).
Za razliko od regresijske analize, kjer je vrstni red vrstic v opazovalni matriki lahko poljuben, je pri časovni vrsti vrstni red pomemben, zato je zanimiv odnos med vrednostmi v različnih časovnih točkah.
Če so vrednosti serije znane v posameznih časovnih točkah, se taka serija imenuje diskretna, Za razliko od neprekinjeno, katerih vrednosti so znane v vsakem trenutku. Imenujmo interval med dvema zaporednima časovnima trenutkoma taktnost(korak). Tu bomo obravnavali predvsem diskretne časovne vrste s fiksno dolžino urnega cikla, vzeto kot štetno enoto. Upoštevajte, da so časovne vrste ekonomskih indikatorjev praviloma diskretne.
Vrednosti serije so lahko neposredno merljivo(cena, donosnost, temperatura), oz agregirano (kumulativno), na primer izhodna prostornina; razdalja, ki jo prepotujejo tovorni prevozniki v časovnem koraku.
Če so vrednosti serije določene z deterministično matematično funkcijo, se serija imenuje deterministični. Če je te vrednosti mogoče opisati le z uporabo verjetnostnih modelov, se imenuje časovna vrsta naključen.
Pojav, ki se pojavi skozi čas, se imenuje postopek, zato lahko govorimo o determinističnih ali naključnih procesih. V slednjem primeru se izraz pogosto uporablja "stohastični proces". Analiziran segment časovne vrste je mogoče obravnavati kot določeno izvedbo (vzorec) stohastičnega procesa, ki ga proučujemo, generiran s skritim verjetnostnim mehanizmom.
Časovne vrste se pojavljajo na številnih predmetnih področjih in imajo različne narave. Za njihovo proučevanje so bile predlagane različne metode, zaradi česar je teorija časovnih vrst zelo obsežna disciplina. Tako lahko glede na vrsto časovne vrste ločimo naslednje dele teorije analize časovnih vrst:
– stacionarni naključni procesi, ki opisujejo zaporedja naključnih spremenljivk, katerih verjetnostne lastnosti se s časom ne spreminjajo. Podobni procesi so razširjeni v radiotehniki, meteorologiji, seizmologiji itd.
– difuzijski procesi, ki potekajo pri medsebojnem prežemanju tekočin in plinov.
– točkovni procesi, ki opisujejo zaporedja dogodkov, kot so prejem zahtevkov za storitev, naravne nesreče in nesreče, ki jih povzroči človek. Podobne procese preučuje teorija čakalnih vrst.
Omejili se bomo na obravnavo aplikativnih vidikov analize časovnih vrst, ki so uporabni pri reševanju praktičnih problemov v ekonomiji in financah. Glavni poudarek bo na metodah za izbiro matematičnega modela za opis časovne vrste in napovedovanje njenega obnašanja.
1.Cilji, metode in stopnje analize časovnih vrst
Praktična študija časovne vrste vključuje prepoznavanje lastnosti serije in sklepanje o verjetnostnem mehanizmu, ki ustvarja to vrsto. Glavni cilji preučevanja časovnih vrst so naslednji:
– opis značilnih lastnosti serije v zgoščeni obliki;
– izdelava modela časovne vrste;
– napoved prihodnjih vrednosti na podlagi preteklih opazovanj;
– nadzor nad procesom, ki generira časovno vrsto z vzorčenjem signalov, ki opozarjajo na bližajoče se neželene dogodke.
Doseganje zastavljenih ciljev ni vedno mogoče, tako zaradi pomanjkanja začetnih podatkov (premajhno trajanje opazovanja) kot zaradi variabilnosti statistične strukture serije skozi čas.
Našteti cilji v veliki meri narekujejo zaporedje stopenj analize časovnih vrst:
1) grafični prikaz in opis obnašanja serije;
2) identifikacija in izključitev pravilnih, nenaključnih komponent serije, ki so odvisne od časa;
3) študija naključne komponente časovne vrste, ki ostane po odstranitvi redne komponente;
4) konstrukcija (izbira) matematičnega modela za opis naključne komponente in preverjanje njegove ustreznosti;
5) napovedovanje prihodnjih vrednosti serije.
Pri analizi časovnih vrst se uporabljajo različne metode, med katerimi so najpogostejše:
1) korelacijska analiza, ki se uporablja za identifikacijo značilnih značilnosti niza (periodičnosti, trendi itd.);
2) spektralna analiza, ki omogoča iskanje periodičnih komponent časovne vrste;
3) metode glajenja in filtriranja, namenjene preoblikovanju časovnih vrst za odstranitev visokofrekvenčnih in sezonskih nihanj;
5) metode napovedovanja.
2. Strukturne komponente časovne vrste
Kot smo že omenili, je v modelu časovne vrste običajno razlikovati dve glavni komponenti: deterministično in naključno (slika). Pod deterministično komponento časovne vrste
razumejo številčno zaporedje, katerega elementi so izračunani po določenem pravilu v odvisnosti od časa t. Z izločitvijo deterministične komponente iz podatkov dobimo serijo, ki niha okoli ničle, kar lahko v enem skrajnem primeru predstavlja čisto naključne skoke, v drugem pa gladko nihajno gibanje. V večini primerov bo nekaj vmes: nekaj nepravilnosti in nekaj sistematičnega učinka zaradi odvisnosti zaporednih členov serije.Po drugi strani lahko deterministična komponenta vsebuje naslednje strukturne komponente:
1) trend g, ki je gladka sprememba procesa skozi čas in je posledica delovanja dolgoročnih dejavnikov. Kot primer takih dejavnikov v ekonomiji lahko navedemo: a) spremembe v demografskih značilnostih prebivalstva (število, starostna struktura); b) tehnološki in gospodarski razvoj; c) rast potrošnje.
2) sezonski učinek s, povezana s prisotnostjo dejavnikov, ki delujejo ciklično z vnaprej določeno frekvenco. Niz ima v tem primeru hierarhično časovno lestvico (na primer, znotraj leta so sezone, povezane z letnimi časi, četrtletji, meseci) in podobni učinki se odvijajo na istih točkah v nizu.
riž. Strukturne komponente časovne vrste.
Tipični primeri sezonskega učinka: spremembe zastojev na avtocestah čez dan, po dnevih v tednu, po letnem času, največja prodaja blaga za šolarje konec avgusta - začetek septembra. Sezonska komponenta se lahko sčasoma spreminja ali je lebdeče narave. Tako je na grafu obsega prometa letalskih prevoznikov (glej sliko) razvidno, da lokalne konice, ki se pojavijo med velikonočnimi prazniki, "lebdijo" zaradi variabilnosti njihovega časa.
Ciklična komponenta c, ki opisuje dolga obdobja relativnega vzpona in padca in je sestavljen iz ciklov spremenljivega trajanja in amplitude. Podobna komponenta je zelo značilna za številne makroekonomske kazalnike. Ciklične spremembe so tu posledica interakcije ponudbe in povpraševanja, pa tudi zaradi vsiljevanja dejavnikov, kot so izčrpavanje virov, vremenske razmere, spremembe davčne politike itd. Upoštevajte, da je ciklično komponento izjemno težko prepoznati s formalnimi metodami, temelji samo na podatkih preučevane serije.
"Eksplozivna" komponenta jaz, sicer intervencija, ki jo razumemo kot pomemben kratkoročni vpliv na časovno vrsto. Primer intervencije so dogodki "črnega torka" leta 1994, ko je tečaj dolarja narasel za več deset odstotkov na dan.
Naključna komponenta niza odraža vpliv številnih dejavnikov naključne narave in ima lahko raznoliko strukturo, od najpreprostejših v obliki "belega šuma" do zelo kompleksnih, ki jih opisujejo modeli avtoregresivno drsečega povprečja (podrobneje spodaj).
Po identifikaciji strukturnih komponent je potrebno določiti obliko njihovega pojavljanja v časovni vrsti. Na najvišji ravni predstavitve, ki poudarja samo deterministične in naključne komponente, se običajno uporabljajo aditivni ali multiplikativni modeli.
Aditivni model ima obliko
;množitelj –
Vrste in metode analize časovnih vrst
Časovna vrsta je zbirka zaporednih meritev spremenljivke, izvedenih v enakih časovnih intervalih. Analiza časovnih vrst vam omogoča reševanje naslednjih težav:
- raziskati strukturo časovne serije, ki praviloma vključuje trend - redne spremembe povprečne ravni, pa tudi naključna periodična nihanja;
- raziskovanje vzročno-posledičnih odnosov med procesi, ki določajo spremembe v vrstah, ki se kažejo v korelacijah med časovnimi vrstami;
- zgraditi matematični model procesa, ki ga predstavlja časovna vrsta;
- preoblikovati časovno vrsto z orodji za glajenje in filtriranje;
- napovedati prihodnji razvoj procesa.
Velik del znanih metod je namenjen analizi stacionarnih procesov, katerih statistične lastnosti, za katere je značilna normalna porazdelitev srednje vrednosti in variance, so konstantne in se s časom ne spreminjajo.
Toda serije imajo pogosto nestacionarni značaj. Nestacionarnost je mogoče odpraviti na naslednji način:
- odštejemo trend, tj. spremembe povprečne vrednosti, predstavljene z neko deterministično funkcijo, ki jo je mogoče izbrati z regresijsko analizo;
- izvedite filtriranje s posebnim nestacionarnim filtrom.
Standardizirati časovne vrste za enotnost metod
analizo je priporočljivo izvesti njihovo splošno ali sezonsko centriranje z deljenjem s povprečno vrednostjo, pa tudi normalizacijo z deljenjem s standardnim odklonom.
Centriranje niza odstrani povprečje, ki ni nič, zaradi česar je rezultate težko interpretirati, na primer pri spektralni analizi. Namen normalizacije je preprečiti operacije z velikimi števili v izračunih, ki lahko privedejo do zmanjšanja natančnosti izračunov.
Po teh predhodnih transformacijah časovne vrste je mogoče zgraditi njen matematični model, po katerem se izvaja napovedovanje, tj. Dobili smo nekaj nadaljevanja časovne serije.
Da se rezultat napovedi primerja z izvirnimi podatki, je treba na njem narediti transformacije, ki so inverzne tistim, ki so bile izvedene.
V praksi se najpogosteje uporabljajo metode modeliranja in napovedovanja, kot pomožni metodi pa korelacijska in spektralna analiza. To je zabloda. Metode za napovedovanje razvoja povprečnih trendov omogočajo pridobivanje ocen s pomembnimi napakami, zaradi česar je zelo težko napovedati prihodnje vrednosti spremenljivke, ki jo predstavlja časovna vrsta.
Metode korelacije in spektralne analize omogočajo prepoznavanje različnih, vključno z inercialnimi, lastnostmi sistema, v katerem se razvijajo proučevani procesi. Uporaba teh metod omogoča, da iz trenutne dinamike procesov z zadostno zanesljivostjo ugotovimo, kako in s kakšnim zamikom bo znana dinamika vplivala na prihodnji razvoj procesov. Za dolgoročno napovedovanje te vrste analiz zagotavljajo dragocene rezultate.
Analiza trendov in napovedovanje
Analiza trenda je namenjena preučevanju sprememb povprečne vrednosti časovne serije z izgradnjo matematičnega modela trenda in na tej podlagi napovedovanju prihodnjih vrednosti serije. Analiza trendov se izvaja s konstruiranjem preprostih linearnih ali nelinearnih regresijskih modelov.
Uporabljeni začetni podatki so dve spremenljivki, od katerih je ena vrednost časovnega parametra, druga pa dejanske vrednosti časovne vrste. Med postopkom analize lahko:
- preizkusite več modelov matematičnih trendov in izberite tistega, ki natančneje opisuje dinamiko serije;
- zgraditi napoved prihodnjega obnašanja časovne vrste na podlagi izbranega trendnega modela z določeno verjetnostjo zaupanja;
- odstranite trend iz časovne vrste, da zagotovite njegovo stacionarnost, potrebno za korelacijsko in spektralno analizo, za to pa je po izračunu regresijskega modela potrebno shraniti ostanke za izvedbo analize.
Različne funkcije in kombinacije se uporabljajo kot modeli trendov, pa tudi serije moči, včasih imenovane polinomski modeli. Največjo natančnost zagotavljajo modeli v obliki Fourierjevih vrst, vendar le malo statističnih paketov omogoča uporabo takih modelov.
Naj ponazorimo izpeljavo modela serijskega trenda. Uporabljamo niz podatkov o ameriškem bruto nacionalnem proizvodu za obdobje 1929-1978. po trenutnih cenah. Zgradimo polinomski regresijski model. Natančnost modela se je povečevala, dokler stopnja polinoma ni dosegla pete:
Y = 145,6 - 35,67* + 4,59* 2 - 0,189* 3 + 0,00353x 4 + 0,000024* 5,
(14,9) (5,73) (0,68) (0,033) (0,00072) (0,0000056)
Kje U - BNP, milijarde dolarjev;
* - leta šteta od prvega leta 1929;
Pod koeficienti so njihove standardne napake.
Standardne napake koeficientov modela so majhne in ne dosegajo vrednosti, ki so enake polovici vrednosti koeficientov modela. To kaže na dobro kakovost modela.
Koeficient determinacije modela, enak kvadratu reduciranega koeficienta multiple korelacije, je bil 99 %. To pomeni, da model pojasni 99 % podatkov. Standardna napaka modela se je izkazala za 14,7 milijarde, stopnja pomembnosti ničelne hipoteze - hipoteze brez povezave - pa manj kot 0,1%.
S pomočjo dobljenega modela je možno podati napoved, ki je v primerjavi z dejanskimi podatki podana v tabeli. PZ. 1.
Napoved in dejanska velikost ameriškega BNP, milijarde dolarjev.
Preglednica PZ.1
Napoved, pridobljena s polinomskim modelom, ni preveč natančna, kar dokazujejo podatki v tabeli.
Korelacijska analiza
Korelacijska analiza je potrebna za identifikacijo korelacije in njihovih zamikov – zamikov v njihovi periodičnosti. Komunikacija v enem procesu se imenuje avtokorelacija, in povezava med dvema procesoma, za katero je značilen niz - navzkrižne korelacije. Visoka stopnja korelacije lahko služi kot pokazatelj vzročno-posledičnih zvez, interakcij znotraj enega procesa, med dvema procesoma, vrednost zamika pa kaže na časovni zamik pri prenosu interakcije.
Značilno je, da v procesu izračunavanja vrednosti korelacijske funkcije na Za V koraku se izračuna korelacija med spremenljivkama po dolžini odseka / = 1,..., (p - k) prva vrsta X in segment / = Za,..., p druga vrsta K Dolžina segmentov se tako spremeni.
Rezultat je za praktično interpretacijo težko interpretirana vrednost, ki spominja na parametrični korelacijski koeficient, vendar mu ni enaka. Zato so možnosti korelacijske analize, katere metodologija se uporablja v številnih statističnih paketih, omejene na ozek nabor razredov časovnih vrst, ki za večino gospodarskih procesov niso značilni.
Ekonomiste v korelacijski analizi zanima preučevanje zamikov pri prenosu vpliva z enega procesa na drugega ali vpliv začetne motnje na kasnejši razvoj istega procesa. Za rešitev takšnih težav je bila predlagana sprememba znane metode, imenovane intervalna korelacija".
Kulaičev A.P. Metode in orodja za analizo podatkov v okolju Windows. - M.: Informatika in računalniki, 2003.
Intervalna korelacijska funkcija je zaporedje korelacijskih koeficientov, izračunanih med fiksnim segmentom prve vrstice dane velikosti in položaja ter enako velikimi segmenti druge vrstice, izbranimi z zaporednimi premiki od začetka serije.
Definiciji sta dodana dva nova parametra: dolžina premaknjenega fragmenta niza in njegov začetni položaj, uporabljena pa je tudi definicija Pearsonovega korelacijskega koeficienta, sprejetega v matematični statistiki. Zaradi tega so izračunane vrednosti primerljive in enostavne za interpretacijo.
Običajno je za izvedbo analize potrebno izbrati eno ali dve spremenljivki za avtokorelacijsko ali navzkrižno korelacijsko analizo ter nastaviti naslednje parametre:
Dimenzija časovnega koraka analizirane serije za ujemanje
rezultati z realno časovnico;
Dolžina premaknjenega fragmenta prve vrstice v obliki številke, vključene v
elementov serije;
Premik tega fragmenta glede na začetek vrstice.
Seveda je treba izbrati možnost intervalne korelacije ali drugo korelacijsko funkcijo.
Če je za analizo izbrana ena spremenljivka, se vrednosti avtokorelacijske funkcije izračunajo za zaporedno naraščajoče zamike. Avtokorelacijska funkcija nam omogoča, da ugotovimo, v kolikšni meri se dinamika sprememb v danem fragmentu reproducira v njegovih segmentih, premaknjenih v času.
Če sta za analizo izbrani dve spremenljivki, se vrednosti navzkrižne korelacijske funkcije izračunajo za zaporedno naraščajoče zamike - premike druge od izbranih spremenljivk glede na prvo. Navzkrižna korelacijska funkcija nam omogoča, da ugotovimo, v kolikšni meri se spremembe v fragmentu prve vrstice reproducirajo v fragmentih druge vrstice, premaknjenih v času.
Rezultati analize naj vključujejo ocene kritične vrednosti korelacijskega koeficienta g 0 za hipotezo "r 0= 0" na določeni ravni pomembnosti. To vam omogoča, da zanemarite statistično nepomembne korelacijske koeficiente. Potrebno je pridobiti vrednosti korelacijske funkcije, ki označujejo zamike. Grafi funkcij avto- ali navzkrižne korelacije so zelo uporabni in vizualni.
Naj uporabo navzkrižne korelacijske analize ponazorimo s primerom. Ocenimo razmerje med stopnjami rasti BNP ZDA in ZSSR v 60 letih od 1930 do 1979. Za pridobitev značilnosti dolgoročnih trendov je bil izbran premaknjeni fragment niza dolg 25 let. Kot rezultat so bili pridobljeni korelacijski koeficienti za različne zamike.
Edini zamik, pri katerem se korelacija izkaže za pomembno, je 28 let. Korelacijski koeficient pri tem zamiku je 0,67, mejna, minimalna vrednost pa 0,36. Izkazalo se je, da je bila cikličnost dolgoročnega razvoja gospodarstva ZSSR z zamikom 28 let tesno povezana s cikličnostjo dolgoročnega razvoja gospodarstva ZDA.
Spektralna analiza
Pogost način za analizo strukture stacionarnih časovnih vrst je uporaba diskretne Fourierjeve transformacije za oceno spektralne gostote ali spektra serije. Ta metoda se lahko uporablja:
- pridobiti opisno statistiko ene časovne vrste ali opisno statistiko odvisnosti med dvema časovnima vrstama;
- prepoznati periodične in kvaziperiodične lastnosti nizov;
- preveriti ustreznost modelov, zgrajenih z drugimi metodami;
- za predstavitev stisnjenih podatkov;
- interpolirati dinamiko časovnih vrst.
Natančnost ocen spektralne analize je mogoče povečati z uporabo posebnih metod - z uporabo gladilnih oken in metod povprečenja.
Za analizo morate izbrati eno ali dve spremenljivki in podati je treba naslednje parametre:
- dimenzija časovnega koraka analizirane serije, potrebna za uskladitev rezultatov z realnimi časovnimi in frekvenčnimi lestvicami;
- dolžina Za analizirani segment časovne vrste v obliki števila podatkov, ki so vanj vključeni;
- premik naslednjega segmenta vrstice na 0 glede na prejšnjega;
- vrsta glajenja časovnega okna za zatiranje ti učinek uhajanja moči;
- vrsta povprečenja frekvenčnih karakteristik, izračunanih v zaporednih segmentih časovne serije.
Rezultati analize vključujejo spektrograme - vrednosti amplitudno-frekvenčnih spektralnih karakteristik in vrednosti fazno-frekvenčnih karakteristik. V primeru navzkrižne spektralne analize so rezultati tudi vrednosti prenosne funkcije in koherenčne funkcije spektra. Rezultati analize lahko vključujejo tudi podatke periodograma.
Amplitudno-frekvenčna karakteristika navzkrižnega spektra, imenovana tudi navzkrižna spektralna gostota, predstavlja odvisnost amplitude medsebojnega spektra dveh med seboj povezanih procesov od frekvence. Ta značilnost jasno kaže, pri katerih frekvencah so opazne sinhrone in po velikosti ustrezne spremembe moči v dveh analiziranih časovnih vrstah oziroma kje se nahajajo območja njihovih največjih sovpadanj in največjih odstopanj.
Ponazorimo uporabo spektralne analize s primerom. Analizirajmo valove gospodarskih razmer v Evropi v obdobju začetka industrijskega razvoja. Za analizo uporabljamo nezglajeno časovno vrsto indeksov cen pšenice, ki jih povpreči Beveridge na podlagi podatkov s 40 evropskih trgov v 370 letih od 1500 do 1869. Dobimo spektre
serija in njeni posamezni segmenti v trajanju 100 let vsakih 25 let.
Spektralna analiza vam omogoča, da ocenite moč vsakega harmonika v spektru. Najmočnejši so valovi s 50-letno periodo, ki jih je, kot je znano, odkril N. Kondratiev 1 in dobil njegovo ime. Analiza nam omogoča, da ugotovimo, da niso nastale ob koncu 17. - začetku 19. stoletja, kot menijo mnogi ekonomisti. Nastajali so od leta 1725 do 1775.
Konstrukcija avtoregresijskih in integriranih modelov drsečega povprečja ( ARIMA) veljajo za uporabne za opisovanje in napovedovanje stacionarnih časovnih vrst in nestacionarnih vrst, ki kažejo enakomerna nihanja okoli spreminjajoče se srednje vrednosti.
Modeli ARIMA sta kombinaciji dveh modelov: avtoregresivni (AR) in drseče povprečje (drseče povprečje - MA).
Modeli drsečega povprečja (MA) predstavljajo stacionarni proces kot linearno kombinacijo zaporednih vrednosti tako imenovanega "belega šuma". Takšni modeli se izkažejo za uporabne tako kot samostojni opisi stacionarnih procesov kot tudi kot dodatek k avtoregresijskim modelom za podrobnejši opis komponente šuma.
Algoritmi za izračun parametrov modela MA so zelo občutljivi na nepravilno izbiro števila parametrov za določeno časovno vrsto, predvsem v smeri njihovega povečevanja, kar lahko povzroči nekonvergenco izračunov. Priporočljivo je, da na začetnih stopnjah analize ne izberete modela drsečega povprečja z velikim številom parametrov.
Predhodna ocena - prva faza analize z uporabo modela ARIMA. Postopek predhodnega ocenjevanja se zaključi, ko je sprejeta hipoteza o ustreznosti modela časovni vrsti ali ko je izčrpano dovoljeno število parametrov. Posledično rezultati analize vključujejo:
- vrednosti parametrov avtoregresijskega modela in modela drsečega povprečja;
- za vsak korak napovedi so navedeni povprečna vrednost napovedi, standardna napaka napovedi, interval zaupanja napovedi za določeno stopnjo pomembnosti;
- statistika za oceno stopnje pomembnosti hipoteze nekoreliranih ostankov;
- grafikoni časovnih vrst, ki kažejo standardno napako napovedi.
- Precejšen del gradiva v razdelku PZ temelji na določilih knjig: Basovski L.E. Napovedovanje in načrtovanje v tržnih razmerah. - M.: INFRA-M, 2008. Gilmore R. Uporabna teorija nesreč: V 2 knjigah. Knjiga 1/ Per. iz angleščine M.: Mir, 1984.
- Jean Baptiste Joseph Fourier (Jean Baptiste Joseph Fourier; 1768-1830) - francoski matematik in fizik.
- Nikolaj Dmitrijevič Kondratiev (1892-1938) - ruski in sovjetski ekonomist.
ANALIZA ČASOVNE VRSTE
UVOD
POGLAVJE 1. ANALIZA ČASOVNE VRSTE
1.1 ČASOVNA VRSTA IN NJENI OSNOVNI ELEMENTI
1.2 AVTOKORELACIJA RAVNI ČASOVNE VRSTE IN IDENTIFIKACIJA NJENE STRUKTURE
1.3 MODELIRANJE TRENDOV ČASOVNE VRSTE
1.4 METODA najmanjših kvadratov
1.5 ZMANJŠANJE ENAČBE TRENDA NA LINEARNO OBLIKO
1.6 OCENA PARAMETROV REGRESIJSKE ENAČBE
1.7 MODELI ADITIVNEGA IN MULTIPLIKATNEGA ČASOVNE VRSTE
1.8 STACIONARNA ČASOVNA VRSTA
1.9 UPORABA HITRO FOURIERJEVO TRANSFORMACIJO ZA STACIONARNO ČASOVNO VRSTO
1.10 AVTOKORELACIJA RESIDUALOV. DURBIN-WATSONOV KRITERIJ
Uvod
Skoraj na vsakem področju obstajajo pojavi, ki so zanimivi in pomembni za preučevanje v njihovem razvoju in spreminjanju skozi čas. V vsakdanjem življenju so lahko zanimive na primer meteorološke razmere, cene posameznega izdelka, nekatere značilnosti zdravstvenega stanja posameznika ... Vse to se skozi čas spreminja. Sčasoma se spreminja poslovna dejavnost, način posameznega proizvodnega procesa, globina človekovega spanca in dojemanje televizijskega programa. Predstavlja celoto meritev katere koli značilnosti te vrste v določenem časovnem obdobju Časovne serije.
Nabor obstoječih metod za analizo takšnih nizov opazovanj se imenuje analiza časovnih vrst.
Glavna značilnost, po kateri se analiza časovnih vrst razlikuje od drugih vrst statističnih analiz, je pomembnost vrstnega reda opazovanj. Če so v mnogih problemih opazovanja statistično neodvisna, so v časovnih serijah praviloma odvisna, naravo te odvisnosti pa lahko določimo s položajem opazovanj v zaporedju. Narava niza in struktura procesa, ki generira niz, lahko vnaprej določita vrstni red, v katerem je zaporedje oblikovano.
Tarča Delo je sestavljeno iz pridobitve modela za diskretno časovno vrsto v časovni domeni, ki ima maksimalno enostavnost in minimalno število parametrov ter hkrati ustrezno opisuje opazovanja.
Pridobitev takega modela je pomembna iz naslednjih razlogov:
1) lahko pomaga razumeti naravo sistema, ki ustvarja časovne vrste;
2) nadzor procesa, ki generira serijo;
3) se lahko uporablja za optimalno napovedovanje prihodnjih vrednosti časovnih vrst;
Časovne vrste so najbolje opisane nestacionarni modeli, v katerem se trendi in druge psevdostabilne značilnosti, ki se lahko spreminjajo skozi čas, obravnavajo kot statistični in ne deterministični pojavi. Poleg tega so časovne vrste, povezane z gospodarstvom, pogosto opazne sezonsko ali periodične komponente; te komponente se lahko spreminjajo skozi čas in jih je treba opisati s cikličnimi statističnimi (po možnosti nestacionarnimi) modeli.
Naj bo opazovana časovna vrsta y 1 , y 2 , . . ., y n . Ta vnos bomo razumeli na naslednji način. Obstaja T števil, ki predstavljajo opazovanje neke spremenljivke v T enako oddaljenih trenutkih časa. Zaradi udobja so ti trenutki oštevilčeni s celimi števili 1, 2, . . .,T. Dokaj splošen matematični (statistični ali verjetnostni) model je model oblike:
y t = f(t) + u t , t = 1, 2, . . ., T.
V tem modelu se opazovana vrsta obravnava kot vsota nekega popolnoma determinističnega zaporedja (f(t)), ki ga lahko imenujemo matematična komponenta, in naključnega zaporedja (u t), ki se podreja nekemu verjetnostnemu zakonu. (Včasih se za ti dve komponenti uporabljata izraza signal in šum). Te komponente opazovane serije so neopazovane; so teoretične količine. Natančen pomen te razčlenitve ni odvisen samo od samih podatkov, ampak deloma tudi od tega, kaj pomeni ponovitev poskusa, iz katerega so ti podatki rezultat. Tu se uporablja tako imenovana "frekvenčna" interpretacija. Verjame se, da je vsaj načeloma možno ponoviti celotno situacijo in pridobiti nove nize opazovanj. Naključne komponente lahko med drugim vključujejo napake pri opazovanju.
Ta članek obravnava model časovne vrste, v katerem je naključna komponenta prekrita s trendom in tvori naključni stacionarni proces. V takem modelu se predpostavlja, da potek časa na noben način ne vpliva na naključno komponento. Natančneje, predpostavlja se, da je matematično pričakovanje (to je povprečna vrednost) naključne komponente identično enako nič, varianca je enaka neki konstanti in da vrednosti u t v različnih časih niso korelirane. Tako je vsaka časovna odvisnost vključena v sistematično komponento f(t). Zaporedje f(t) je lahko odvisno od nekaterih neznanih koeficientov in znanih količin, ki se spreminjajo skozi čas. V tem primeru se imenuje "regresijska funkcija". Metode statističnega sklepanja za koeficiente regresijske funkcije so uporabne na številnih področjih statistike. Edinstvenost metod, ki se nanašajo posebej na časovne vrste, je v tem, da proučujejo tiste modele, pri katerih so zgoraj omenjene količine, ki se skozi čas spreminjajo, znane funkcije t.
Poglavje 1. Analiza časovnih vrst
1.1 Časovna vrsta in njeni glavni elementi
Časovna vrsta je zbirka vrednosti katerega koli kazalnika za več zaporednih trenutkov ali časovnih obdobij. Vsaka raven časovne vrste se oblikuje pod vplivom velikega števila dejavnikov, ki jih lahko razdelimo v tri skupine:
· dejavniki, ki oblikujejo trend serije;
· dejavniki, ki tvorijo ciklična nihanja serije;
· naključni dejavniki.
Z različnimi kombinacijami teh dejavnikov v proučevanem procesu ali pojavu ima lahko odvisnost ravni serije od časa različne oblike. Prvič, ima večina časovnih vrst ekonomskih kazalnikov trend, ki označuje dolgoročni kumulativni vpliv številnih dejavnikov na dinamiko preučevanega kazalnika. Očitno je, da lahko ti dejavniki, če jih vzamemo ločeno, večsmerno vplivajo na preučevani kazalnik. Vendar pa skupaj tvorijo naraščajoči ali padajoči trend.
Drugič, indikator, ki se proučuje, je lahko podvržen cikličnim nihanjem. Ta nihanja so lahko sezonska, saj so dejavnosti številnih gospodarskih in kmetijskih sektorjev odvisne od letnega časa. Če so na voljo velike količine podatkov v daljših časovnih obdobjih, je mogoče prepoznati ciklična nihanja, povezana s celotno dinamiko časovne vrste.
Nekatere časovne serije ne vsebujejo trenda ali ciklične komponente, vsak naslednji nivo pa se oblikuje kot vsota povprečnega nivoja niza in neke (pozitivne ali negativne) naključne komponente.
V večini primerov je dejansko raven časovne vrste mogoče predstaviti kot vsoto ali produkt trendnih, cikličnih in naključnih komponent. Imenuje se model, v katerem je časovna vrsta predstavljena kot vsota naštetih komponent aditivni modelČasovne serije. Imenuje se model, v katerem je časovna vrsta predstavljena kot produkt naštetih komponent multiplikativni modelČasovne serije. Glavna naloga statistične študije posamezne časovne serije je identificirati in kvantificirati vsako od zgoraj naštetih komponent, da bi pridobljene informacije uporabili za napovedovanje prihodnjih vrednosti serije.
1.2 Avtokorelacija ravni časovne vrste in identifikacija njene strukture
Če v časovni seriji obstaja trend in ciklična nihanja, so vrednosti vsake naslednje ravni serije odvisne od prejšnjih. Korelacijska odvisnost med zaporednimi nivoji časovne vrste se imenuje avtokorelacija nivojev serije.
Kvantitativno ga je mogoče izmeriti z uporabo linearnega korelacijskega koeficienta med ravnmi prvotne časovne serije in ravnmi te serije, premaknjene za več korakov v času.
Ena od delovnih formul za izračun avtokorelacijskega koeficienta je:
(1.2.1)Kot spremenljivko x bomo obravnavali vrsto y 2, y 3, ..., y n; kot spremenljivka y – serija y 1, y 2, . . . ,y n – 1 . Potem bo zgornja formula dobila obliko:
(1.2.2)Podobno je mogoče določiti avtokorelacijske koeficiente drugega in višjega reda. Tako avtokorelacijski koeficient drugega reda označuje tesnost povezave med nivojema y t in y t – 1 in je določen s formulo
(1.2.3)Pokliče se število obdobij, za katere se izračuna avtokorelacijski koeficient lagom. Ko se zamik poveča, se število parov vrednosti, iz katerih se izračuna avtokorelacijski koeficient, zmanjša. Nekateri avtorji menijo, da je za zagotavljanje statistične zanesljivosti avtokorelacijskih koeficientov priporočljivo uporabiti pravilo - največji zamik ne sme biti večji od (n/4).

