Metody analizy szeregów czasowych. Streszczenie: Szereg czasowy Analiza wykresu pokazuje
Analiza szeregów czasowych umożliwia badanie wydajności w czasie. Szereg czasowy to wartości liczbowe wskaźnika statystycznego, ułożone w porządku chronologicznym.
Dane takie są powszechne w różnych obszarach działalności człowieka: dzienne ceny akcji, kursy walut, kwartalne, roczne wielkości sprzedaży, produkcja itp. Typowy szereg czasowy w meteorologii, taki jak miesięczne opady.
Szeregi czasowe w Excelu
Jeśli zapiszesz wartości procesu w określonych odstępach czasu, otrzymasz elementy szeregu czasowego. Próbują podzielić ich zmienność na składowe regularne i losowe. Regularne zmiany członków serii są z reguły przewidywalne.
Zróbmy analizę szeregów czasowych w Excelu. Przykład: sieć handlowa analizuje dane dotyczące sprzedaży towarów ze sklepów zlokalizowanych w miastach poniżej 50 000 mieszkańców. Okres – 2012-2015 Zadanie polega na identyfikacji głównego trendu rozwojowego.
Wprowadźmy dane sprzedażowe do tabeli Excel:
W zakładce „Dane” kliknij przycisk „Analiza danych”. Jeśli nie jest widoczny, przejdź do menu. „Opcje programu Excel” - „Dodatki”. Na dole kliknij „Przejdź” do „Dodatki Excel” i wybierz „Pakiet analityczny”.
Podłączenie ustawienia „Analiza danych” zostało szczegółowo opisane.
Wymagany przycisk pojawi się na wstążce.

Z proponowanej listy narzędzi do analizy statystycznej wybierz „Wygładzanie wykładnicze”. Ta metoda niwelacji jest odpowiednia dla naszych szeregów czasowych, których wartości znacznie się zmieniają.

Wypełnij okno dialogowe. Przedział wejściowy – zakres z wartościami sprzedaży. Współczynnik tłumienia – współczynnik wygładzania wykładniczego (domyślnie – 0,3). Zakres wyjściowy – odniesienie do lewej górnej komórki zakresu wyjściowego. Program umieści tu wygładzone poziomy i samodzielnie określi wielkość. Zaznacz pola „Wyjście wykresu”, „Błędy standardowe”.

Zamknij okno dialogowe, klikając OK. Wyniki analizy:

Aby obliczyć błędy standardowe, Excel używa wzoru: =ROOT(SUMA.RANGE('zakres wartości rzeczywistych'; 'zakres wartości przewidywanych')/ 'rozmiar okna wygładzania'). Na przykład =ROOT(SUMVARE(C3:C5,D3:D5)/3).
Prognozowanie szeregów czasowych w programie Excel
Zróbmy prognozę sprzedaży na podstawie danych z poprzedniego przykładu.
Dodaj linię trendu do wykresu przedstawiającego rzeczywiste wolumeny sprzedaży produktów (prawy przycisk na wykresie – „Dodaj linię trendu”).
Konfigurowanie parametrów linii trendu:

Wybieramy trend wielomianowy, aby zminimalizować błąd modelu prognostycznego.

R2 = 0,9567, co oznacza: wskaźnik ten wyjaśnia 95,67% zmian sprzedaży w czasie.
Równanie trendu to modelowy wzór do obliczania wartości prognoz.

Otrzymujemy dość optymistyczny wynik:
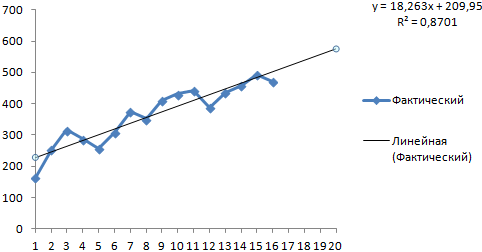
W naszym przykładzie nadal istnieje zależność wykładnicza. Dlatego przy konstruowaniu trendu liniowego pojawia się więcej błędów i niedokładności.
Możesz także użyć funkcji WZROST, aby przewidzieć zależności wykładnicze w programie Excel.
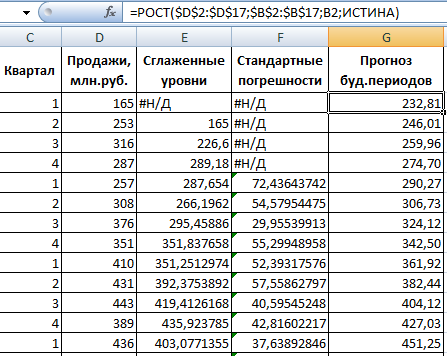
Dla zależności liniowej – TREND.
Tworząc prognozy, nie można stosować tylko jednej metody: istnieje duże prawdopodobieństwo dużych odchyleń i niedokładności.
Cele analizy szeregów czasowych. W praktycznym badaniu szeregów czasowych na podstawie danych ekonomicznych za pewien okres czasu ekonometryk musi wyciągnąć wnioski na temat właściwości tego szeregu i mechanizmu probabilistycznego, który ten szereg generuje. Najczęściej podczas badania szeregów czasowych wyznaczane są następujące cele:
1. Krótki (skompresowany) opis cech charakterystycznych serii.
2. Wybór modelu statystycznego opisującego szereg czasowy.
3. Przewidywanie przyszłych wartości na podstawie przeszłych obserwacji.
4. Sterowanie procesem generującym szeregi czasowe.
W praktyce te i podobne cele są dalekie od zawsze i dalekie od bycia w pełni osiągalnymi. Często utrudniają to niewystarczające obserwacje ze względu na ograniczony czas obserwacji. Jeszcze częściej struktura statystyczna szeregu czasowego zmienia się w czasie.
Etapy analizy szeregów czasowych . Zazwyczaj w praktycznej analizie szeregów czasowych realizuje się kolejno następujące etapy:
1. Graficzna reprezentacja i opis zachowania tymczasowego rad.
2. Identyfikacja i usuwanie regularnych, zależnych od czasu składników szeregu czasowego: trendu, składników sezonowych i cyklicznych.
3. Izolacja i usuwanie składników procesu o niskiej lub wysokiej częstotliwości (filtracja).
4. Badanie składnika losowego szeregu czasowego pozostałego po usunięciu wymienionych powyżej składników.
5. Budowa (wybór) modelu matematycznego do opisu składowej losowej i weryfikacja jego adekwatności.
6. Prognozowanie przyszłego rozwoju procesu reprezentowanego przez szereg czasowy.
7. Badanie interakcji między różnymi rady tymczasowe.
Istnieje wiele różnych metod rozwiązywania tych problemów. Spośród nich najczęstsze są następujące:
8. Analiza korelacji, która pozwala na identyfikację istotnych zależności okresowych i ich opóźnień (opóźnień) w obrębie jednego procesu (autokorelacja) lub pomiędzy kilkoma procesami (korelacja krzyżowa).
9. Analiza spektralna, która pozwala znaleźć składowe okresowe i quasi-okresowe szeregu czasowego.
10. Wygładzanie i filtrowanie, mające na celu transformację szeregów czasowych w celu usunięcia z nich wahań o wysokiej częstotliwości lub sezonowości.
12. Prognozowanie, które pozwala na podstawie wybranego modelu zachowania radu tymczasowego przewidzieć jego wartości w przyszłości.
Modele trendów
najprostsze modele trendów . Oto modele trendów najczęściej wykorzystywane w analizie ekonomicznych szeregów czasowych, a także w wielu innych obszarach. Po pierwsze, jest to prosty model liniowy
Gdzie 0, 1– współczynniki modelu trendu;
t – czas.
Jednostką czasu może być godzina, dzień (dni), tydzień, miesiąc, kwartał lub rok. Model 269, pomimo swojej prostoty, okazuje się przydatny w wielu rzeczywistych zastosowaniach. Jeżeli nieliniowy charakter trendu jest oczywisty, odpowiedni może być jeden z poniższych modeli:
1. Wielomian:
(270)
gdzie jest stopniem wielomianu P w problemach praktycznych rzadko przekracza 5;
2. Logarytmiczne:
Model ten jest najczęściej używany w przypadku danych, które mają tendencję do utrzymywania stałego tempa wzrostu;
3. Logistyka:
 (272)
(272)
4. Gompertz
![]() (273), gdzie
(273), gdzie
Dwa ostatnie modele tworzą krzywe trendu w kształcie litery S. Odpowiadają one procesom o stopniowo rosnącym tempie wzrostu w początkowej fazie i stopniowo malejącym tempie wzrostu na końcu. Potrzeba takich modeli wynika z braku możliwości rozwoju wielu procesów gospodarczych przez długi czas przy stałym tempie wzrostu lub według modeli wielomianowych, ze względu na ich dość szybki wzrost (lub spadek).
Podczas prognozowania trend wykorzystuje się przede wszystkim do prognoz długoterminowych. Dokładność prognoz krótkoterminowych opartych wyłącznie na dopasowanej krzywej trendu jest zwykle niewystarczająca.
Do szacowania i usuwania trendów z szeregów czasowych najczęściej stosuje się metodę najmniejszych kwadratów. Metodę tę szczegółowo omówiono w drugiej części podręcznika, w zagadnieniach analizy regresji liniowej. Wartości szeregu czasowego traktowane są jako odpowiedź (zmienna zależna) i czas T– jako czynnik wpływający na reakcję (zmienna niezależna).
Szeregi czasowe charakteryzują się wzajemną zależnością ich członków (przynajmniej niezbyt odległych w czasie) i jest to istotna różnica w stosunku do konwencjonalnej analizy regresji, dla której zakłada się, że wszystkie obserwacje są niezależne. Jednakże szacunki trendów w tych warunkach są zwykle rozsądne, jeśli zostanie wybrany odpowiedni model trendu i jeśli wśród obserwacji nie ma dużych wartości odstających. Wymienione powyżej naruszenia ograniczeń analizy regresji wpływają nie tyle na wartości szacunków, ile na ich właściwości statystyczne. Zatem, jeśli istnieje znacząca zależność pomiędzy wyrazami szeregu czasowego, oszacowania wariancji na podstawie resztowej sumy kwadratów dają błędne wyniki. Przedziały ufności dla współczynników modelu itp. również okazują się nieprawidłowe. W najlepszym przypadku można je uznać za bardzo przybliżone.
Wstęp
W tym rozdziale podjęty został problem opisu uporządkowanych danych uzyskiwanych sekwencyjnie (w czasie). Najogólniej rzecz biorąc, uporządkowanie może zachodzić nie tylko w czasie, ale także w przestrzeni, np. średnica gwintu w funkcji jego długości (przypadek jednowymiarowy), wartość temperatury powietrza w funkcji współrzędnych przestrzennych (trzy -przypadek wymiarowy).
W przeciwieństwie do analizy regresji, gdzie kolejność wierszy w macierzy obserwacji może być dowolna, w szeregach czasowych ważna jest kolejność, dlatego interesująca jest zależność między wartościami w różnych momentach czasu.
Jeżeli w poszczególnych momentach znane są wartości szeregu, wówczas taki szereg nazywa się oddzielny, W odróżnieniu ciągły, których wartości są znane w każdej chwili. Nazwijmy odstęp między dwoma kolejnymi momentami czasu takt(krok). Tutaj będziemy rozważać głównie dyskretne szeregi czasowe o stałej długości cyklu zegara, przyjmowane jako jednostka zliczająca. Należy zauważyć, że szeregi czasowe wskaźników ekonomicznych są z reguły dyskretne.
Wartości serii mogą być bezpośrednio mierzalne(cena, opłacalność, temperatura), lub zagregowany (skumulowany) na przykład głośność wyjściowa; odległość przebyta przez przewoźników ładunków w danym przedziale czasowym.
Jeśli wartości serii są określone przez deterministyczną funkcję matematyczną, wówczas nazywa się serię deterministyczny. Jeżeli wartości te można opisać jedynie za pomocą modeli probabilistycznych, wówczas nazywa się szereg czasowy losowy.
Zjawisko zachodzące w czasie nazywa się proces, dlatego możemy mówić o procesach deterministycznych lub losowych. W tym drugim przypadku często używa się tego terminu "proces stochastyczny". Analizowany segment szeregu czasowego można uznać za szczególną realizację (próbkę) badanego procesu stochastycznego, generowaną przez ukryty mechanizm probabilistyczny.
Szeregi czasowe powstają w wielu obszarach tematycznych i mają różny charakter. Do ich badania zaproponowano różne metody, co czyni teorię szeregów czasowych dyscypliną bardzo obszerną. Zatem w zależności od rodzaju szeregów czasowych można wyróżnić następujące działy teorii analizy szeregów czasowych:
– stacjonarne procesy losowe opisujące ciągi zmiennych losowych, których właściwości probabilistyczne nie zmieniają się w czasie. Podobne procesy są szeroko rozpowszechnione w radiotechnice, meteorologii, sejsmologii itp.
– procesy dyfuzyjne zachodzące podczas wzajemnego przenikania się cieczy i gazów.
– procesy punktowe opisujące sekwencje zdarzeń, takie jak otrzymanie wniosków o świadczenie usług, klęski żywiołowe i spowodowane przez człowieka. Podobne procesy są badane w teorii kolejek.
Ograniczymy się do rozważenia zastosowanych aspektów analizy szeregów czasowych, które są przydatne w rozwiązywaniu praktycznych problemów w ekonomii i finansach. Główny nacisk zostanie położony na metody wyboru modelu matematycznego do opisu szeregu czasowego i przewidywania jego zachowania.
1.Cele, metody i etapy analizy szeregów czasowych
Praktyczne badanie szeregu czasowego polega na identyfikacji właściwości szeregu i wyciąganiu wniosków na temat probabilistycznego mechanizmu, który ten szereg generuje. Główne cele badania szeregów czasowych są następujące:
– opis cech charakterystycznych serii w formie skróconej;
– konstrukcja modelu szeregów czasowych;
– przewidywanie przyszłych wartości na podstawie przeszłych obserwacji;
– sterowanie procesem generującym szeregi czasowe poprzez próbkowanie sygnałów ostrzegających o zbliżającym się niekorzystnym zdarzeniu.
Osiągnięcie założonych celów nie zawsze jest możliwe, zarówno ze względu na brak danych wyjściowych (niewystarczający czas obserwacji), jak i ze względu na zmienność struktury statystycznej szeregu w czasie.
Wymienione cele w dużej mierze wyznaczają kolejność etapów analizy szeregów czasowych:
1) graficzne przedstawienie i opis zachowania serii;
2) identyfikacja i wykluczenie regularnych, nielosowych składników szeregu zależnych od czasu;
3) badanie składnika losowego szeregu czasowego pozostałego po usunięciu składnika regularnego;
4) konstrukcja (wybór) modelu matematycznego opisu składowej losowej i sprawdzenie jego adekwatności;
5) prognozowanie przyszłych wartości szeregu.
Analizując szeregi czasowe stosuje się różne metody, z których najczęstsze to:
1) analiza korelacji służąca identyfikacji cech charakterystycznych szeregu (okresowości, trendów itp.);
2) analiza widmowa, która pozwala znaleźć składowe okresowe szeregu czasowego;
3) metody wygładzania i filtrowania mające na celu transformację szeregów czasowych w celu usunięcia wahań o dużej częstotliwości i sezonowości;
5) metody prognozowania.
2. Elementy strukturalne szeregów czasowych
Jak już wspomniano, w modelu szeregów czasowych zwyczajowo wyróżnia się dwa główne elementy: deterministyczny i losowy (ryc.). W ramach deterministycznego składnika szeregu czasowego
rozumieć ciąg liczbowy, którego elementy są obliczane według określonej reguły w funkcji czasu T. Wykluczając z danych składnik deterministyczny, otrzymujemy szereg oscylujący wokół zera, który w jednym skrajnym przypadku może reprezentować skoki czysto losowe, a w innym płynny ruch oscylacyjny. W większości przypadków będzie coś pomiędzy: pewna nieregularność i pewien systematyczny efekt wynikający z zależności kolejnych wyrazów szeregu.Z kolei składnik deterministyczny może zawierać następujące elementy strukturalne:
1) trend g, czyli płynna zmiana procesu w czasie, spowodowana działaniem czynników długoterminowych. Jako przykład takich czynników w ekonomii można wymienić: a) zmiany cech demograficznych populacji (liczby, struktura wiekowa); b) rozwój technologiczny i gospodarczy; c) wzrost konsumpcji.
2) efekt sezonowy S, wiąże się z obecnością czynników działających cyklicznie z określoną częstotliwością. Szereg w tym przypadku ma hierarchiczną skalę czasową (np. w ciągu roku występują pory roku powiązane z porami roku, kwartałami, miesiącami) i podobne efekty zachodzą w tych samych punktach szeregu.
Ryż. Elementy strukturalne szeregu czasowego.
Typowe przykłady efektu sezonowego: zmiany natężenia ruchu na drogach w ciągu dnia, dnia tygodnia, pory roku, szczytowa sprzedaż towarów dla uczniów na przełomie sierpnia i września. Składnik sezonowy może zmieniać się w czasie lub mieć charakter zmienny. I tak na wykresie natężenia ruchu samolotów pasażerskich (patrz rysunek) widać, że lokalne szczyty występujące w okresie świąt wielkanocnych „unoszą się” ze względu na zmienność jego terminu.
Składnik cykliczny C, opisujący długie okresy względnego wzrostu i spadku i składający się z cykli o zmiennym czasie trwania i amplitudzie. Podobny składnik jest bardzo typowy dla szeregu wskaźników makroekonomicznych. Zmiany cykliczne spowodowane są tu interakcją podaży i popytu, a także nałożeniem czynników takich jak wyczerpywanie się zasobów, warunki pogodowe, zmiany w polityce podatkowej itp. Należy pamiętać, że składnik cykliczny jest niezwykle trudny do zidentyfikowania metodami formalnymi, opiera się wyłącznie na danych badanej serii.
Składnik „wybuchowy”. I, inaczej interwencja, rozumiana jako istotny krótkotrwały wpływ na szereg czasowy. Przykładem interwencji są wydarzenia „Czarnego Wtorku” z 1994 r., kiedy kurs dolara rósł o kilkadziesiąt procent dziennie.
Składowa losowa szeregu odzwierciedla wpływ wielu czynników o charakterze losowym i może mieć zróżnicowaną strukturę, od najprostszej w postaci „białego szumu” po bardzo złożone, opisane modelami autoregresywno-średniej kroczącej (więcej szczegółów poniżej).
Po zidentyfikowaniu elementów konstrukcyjnych należy określić formę ich występowania w szeregu czasowym. Na najwyższym poziomie reprezentacji, wyróżniającym jedynie składowe deterministyczne i losowe, stosuje się zwykle modele addytywne lub multiplikatywne.
Model addytywny ma postać
;multiplikatywny –
Rodzaje i metody analizy szeregów czasowych
Szereg czasowy to zbiór kolejnych pomiarów zmiennej wykonanych w równych odstępach czasu. Analiza szeregów czasowych pozwala rozwiązać następujące problemy:
- zbadać strukturę szeregu czasowego, który z reguły zawiera trend - regularne zmiany średniego poziomu, a także losowe okresowe wahania;
- badać związki przyczynowo-skutkowe pomiędzy procesami determinującymi zmiany w szeregach, które przejawiają się w korelacjach pomiędzy szeregami czasowymi;
- zbudować model matematyczny procesu reprezentowany przez szereg czasowy;
- przekształcać szeregi czasowe za pomocą narzędzi wygładzających i filtrujących;
- przewidzieć przyszły rozwój procesu.
Znaczna część znanych metod przeznaczona jest do analizy procesów stacjonarnych, których właściwości statystyczne, charakteryzujące się rozkładem normalnym według wartości średniej i wariancji, są stałe i nie zmieniają się w czasie.
Ale seriale często mają charakter niestacjonarny. Niestacjonarność można wyeliminować w następujący sposób:
- odejmij trend, tj. zmiany wartości średniej reprezentowane przez jakąś funkcję deterministyczną, którą można wybrać za pomocą analizy regresji;
- wykonać filtrację za pomocą specjalnego filtra niestacjonarnego.
Standaryzacja szeregów czasowych w celu zapewnienia jednolitości metod
analizy wskazane jest przeprowadzenie ich ogólnego lub sezonowego centrowania poprzez podzielenie przez wartość średnią, a także normalizację poprzez podzielenie przez odchylenie standardowe.
Wyśrodkowanie serii usuwa niezerową średnią, co może utrudniać interpretację wyników, na przykład w analizie spektralnej. Celem normalizacji jest uniknięcie operacji na dużych liczbach w obliczeniach, co może prowadzić do zmniejszenia dokładności obliczeń.
Po tych wstępnych przekształceniach szeregu czasowego można zbudować jego model matematyczny, według którego przeprowadza się prognozowanie, tj. Uzyskano pewną kontynuację szeregu czasowego.
Aby wynik prognozy można było porównać z danymi pierwotnymi, należy na nim dokonać przekształceń odwrotnych do dokonanych.
W praktyce najczęściej wykorzystuje się metody modelowania i prognozowania, a jako metody pomocnicze uważa się analizę korelacyjną i spektralną. To złudzenie. Metody prognozowania rozwoju średnich trendów pozwalają na uzyskanie szacunków obarczonych znacznymi błędami, co bardzo utrudnia przewidywanie przyszłych wartości zmiennej reprezentowanej przez szereg czasowy.
Metody korelacji i analizy spektralnej pozwalają na identyfikację różnych, w tym inercyjnych, właściwości układu, w którym rozwijają się badane procesy. Zastosowanie tych metod pozwala z wystarczającą pewnością określić na podstawie aktualnej dynamiki procesów, w jaki sposób i z jakim opóźnieniem znana dynamika wpłynie na przyszły rozwój procesów. W przypadku prognozowania długoterminowego tego typu analizy dostarczają cennych wyników.
Analiza trendów i prognozowanie
Analiza trendu ma na celu badanie zmian wartości średniej szeregu czasowego wraz z budową modelu matematycznego trendu i na tej podstawie prognozowanie przyszłych wartości szeregu. Analizę trendów przeprowadza się poprzez konstruowanie prostych modeli regresji liniowej lub nieliniowej.
Wykorzystywanymi danymi początkowymi są dwie zmienne, z których jedna to wartości parametru czasu, a druga to rzeczywiste wartości szeregu czasowego. Podczas procesu analizy możesz:
- przetestuj kilka modeli trendów matematycznych i wybierz ten, który dokładniej opisuje dynamikę szeregu;
- zbudować prognozę przyszłego zachowania szeregu czasowego w oparciu o wybrany model trendu z określonym prawdopodobieństwem ufności;
- usunąć trend z szeregu czasowego w celu zapewnienia jego stacjonarności, niezbędnej do analizy korelacyjnej i spektralnej, w tym celu po obliczeniu modelu regresji należy zapisać reszty do przeprowadzenia analizy.
Różne funkcje i kombinacje są używane jako modele trendów, a także szeregi potęgowe, czasami nazywane modele wielomianowe. Największą dokładność zapewniają modele w postaci szeregów Fouriera, jednak niewiele pakietów statystycznych pozwala na zastosowanie takich modeli.
Zilustrujmy wyprowadzenie modelu trendu szeregowego. Korzystamy z szeregu danych dotyczących produktu narodowego brutto Stanów Zjednoczonych za lata 1929-1978. po obecnych cenach. Zbudujmy model regresji wielomianowej. Dokładność modelu wzrastała, aż stopień wielomianu osiągnął piątą wartość:
Y = 145,6 - 35,67* + 4,59* 2 - 0,189* 3 + 0,00353x 4 + 0,000024* 5,
(14,9) (5,73) (0,68) (0,033) (0,00072) (0,0000056)
Gdzie Ty - PNB, miliardy dolarów;
* - lata liczone od pierwszego roku 1929;
Poniżej współczynników znajdują się ich błędy standardowe.
Błędy standardowe współczynników modelu są niewielkie i nie osiągają wartości równych połowie wartości współczynników modelu. Świadczy to o dobrej jakości modelu.
Współczynnik determinacji modelu równy kwadratowi zredukowanego współczynnika korelacji wielokrotnej wyniósł 99%. Oznacza to, że model wyjaśnia 99% danych. Błąd standardowy modelu okazał się 14,7 miliarda, a poziom istotności hipotezy zerowej – hipotezy o braku związku – był mniejszy niż 0,1%.
Wykorzystując otrzymany model można przedstawić prognozę, którą w porównaniu z danymi rzeczywistymi przedstawiono w tabeli. PZ. 1.
Prognoza i rzeczywista wielkość amerykańskiego PKB, miliardy dolarów.
Tabela PZ.1
Prognoza uzyskana za pomocą modelu wielomianowego nie jest zbyt dokładna, o czym świadczą dane zaprezentowane w tabeli.
Analiza korelacji
Analiza korelacji jest konieczna do identyfikacji korelacji i ich opóźnień – opóźnień w ich okresowości. Nazywa się komunikację w jednym procesie autokorelacja, oraz połączenie dwóch procesów charakteryzujących się szeregiem - korelacje krzyżowe. Wysoki poziom korelacji może służyć jako wskaźnik związków przyczynowo-skutkowych, interakcji w ramach jednego procesu, pomiędzy dwoma procesami, a wartość opóźnienia wskazuje na opóźnienie czasowe w transmisji interakcji.
Zazwyczaj w procesie obliczania wartości funkcji korelacji na Do W kroku th obliczana jest korelacja pomiędzy zmiennymi na długości odcinka / = 1,..., (p-k) pierwszy rząd X i segment / = Do,..., P drugi rząd K W ten sposób zmienia się długość segmentów.
Wynik jest wartością trudną do praktycznej interpretacji, przypominającą parametryczny współczynnik korelacji, ale nie tożsamą z nim. Dlatego możliwości analizy korelacji, której metodologia stosowana jest w wielu pakietach statystycznych, ograniczają się do wąskiego zakresu klas szeregów czasowych, które nie są typowe dla większości procesów gospodarczych.
Ekonomiści zajmujący się analizą korelacji są zainteresowani badaniem opóźnień w przenoszeniu wpływu z jednego procesu na drugi lub wpływem początkowego zakłócenia na dalszy rozwój tego samego procesu. Aby rozwiązać takie problemy, zaproponowano modyfikację znanej metody, tzw korelacja interwałowa".
Kulaichev A.P. Metody i narzędzia analizy danych w środowisku Windows. - M.: Informatyka i komputery, 2003.
Przedziałowa funkcja korelacji jest ciągiem współczynników korelacji obliczonych pomiędzy stałym segmentem pierwszego rzędu o danej wielkości i pozycji a jednakowymi segmentami drugiego rzędu, wybieranymi kolejnymi przesunięciami od początku szeregu.
Do definicji dodano dwa nowe parametry: długość przesuniętego fragmentu szeregu i jego położenie początkowe, a także zastosowano definicję współczynnika korelacji Pearsona przyjętą w statystyce matematycznej. Dzięki temu obliczone wartości są porównywalne i łatwe w interpretacji.
Zazwyczaj, aby przeprowadzić analizę, należy wybrać jedną lub dwie zmienne do analizy autokorelacji lub korelacji krzyżowej, a także ustawić następujące parametry:
Wymiar kroku czasowego analizowanego szeregu dla dopasowania
wyniki z rzeczywistą osią czasu;
Długość przesuniętego fragmentu pierwszego rzędu, w postaci liczby zawartej w
elementów serii;
Przesunięcie tego fragmentu względem początku wiersza.
Oczywiście należy wybrać opcję korelacji przedziałowej lub innej funkcji korelacji.
Jeżeli do analizy zostanie wybrana jedna zmienna, wówczas wartości funkcji autokorelacji wyliczane są dla sukcesywnie rosnących opóźnień. Funkcja autokorelacji pozwala określić, w jakim stopniu dynamika zmian danego fragmentu jest odtwarzana w jego własnych segmentach przesuniętych w czasie.
Jeżeli do analizy zostaną wybrane dwie zmienne, to wartości funkcji korelacji krzyżowej wyliczane są dla sukcesywnie narastających opóźnień – przesunięć drugiej z wybranych zmiennych względem pierwszej. Funkcja korelacji krzyżowej pozwala określić, w jakim stopniu zmiany we fragmencie pierwszego rzędu odtwarzają się we fragmentach drugiego rzędu przesuniętych w czasie.
Wyniki analizy powinny zawierać szacunki wartości krytycznej współczynnika korelacji g 0 dla hipotezy „r 0= 0” na pewnym poziomie istotności. Dzięki temu można pominąć nieistotne statystycznie współczynniki korelacji. Konieczne jest uzyskanie wartości funkcji korelacji wskazującej opóźnienia. Wykresy funkcji autokorelacji lub korelacji krzyżowej są bardzo przydatne i wizualne.
Zilustrujmy zastosowanie analizy korelacji krzyżowych na przykładzie. Oceńmy relację między tempem wzrostu PKB USA i ZSRR na przestrzeni 60 lat od 1930 do 1979 roku. Aby uzyskać charakterystykę trendów długoterminowych, przesunięty fragment szeregu wybrano na okres 25 lat. W rezultacie uzyskano współczynniki korelacji dla różnych opóźnień.
Jedyne opóźnienie, przy którym korelacja okazuje się istotna, to 28 lat. Współczynnik korelacji przy tym opóźnieniu wynosi 0,67, natomiast wartość progowa, minimalna wynosi 0,36. Okazuje się, że cykliczność długoterminowego rozwoju gospodarki ZSRR z 28-letnim opóźnieniem była ściśle powiązana z cyklicznością długoterminowego rozwoju gospodarki USA.
Analiza spektralna
Powszechnym sposobem analizy struktury stacjonarnych szeregów czasowych jest użycie dyskretnej transformaty Fouriera do oszacowania gęstości widmowej lub widma szeregu. Metodę tę można zastosować:
- w celu uzyskania statystyki opisowej jednego szeregu czasowego lub statystyki opisowej zależności pomiędzy dwoma szeregami czasowymi;
- identyfikować własności okresowe i quasi-okresowe szeregów;
- sprawdzenie adekwatności modeli zbudowanych innymi metodami;
- do prezentacji skompresowanych danych;
- do interpolacji dynamiki szeregów czasowych.
Dokładność szacunków analizy widmowej można zwiększyć poprzez zastosowanie specjalnych metod - zastosowanie okien wygładzających i metod uśredniania.
Do analizy należy wybrać jedną lub dwie zmienne i określić następujące parametry:
- wymiar kroku czasowego analizowanego szeregu, niezbędny do skoordynowania wyników ze skalami czasu rzeczywistego i częstotliwości;
- długość Do analizowany segment szeregu czasowego, w postaci liczby zawartych w nim danych;
- przesunięcie kolejnego segmentu rzędu do 0 w stosunku do poprzedniego;
- rodzaj wygładzania okna czasowego, mający na celu tłumienie tzw efekt wycieku mocy;
- rodzaj uśredniania charakterystyk częstotliwościowych obliczonych na kolejnych odcinkach szeregu czasowego.
Wyniki analizy obejmują spektrogramy – wartości charakterystyk widma amplitudowo-częstotliwościowego oraz wartości charakterystyk fazowo-częstotliwościowych. W przypadku analizy międzyspektralnej wynikami są także wartości funkcji przenoszenia i funkcji spójności widma. Wyniki analizy mogą również obejmować dane periodogramu.
Charakterystyka amplitudowo-częstotliwościowa widma krzyżowego, zwana także gęstością widmową, reprezentuje zależność amplitudy wspólnego widma dwóch wzajemnie powiązanych procesów od częstotliwości. Charakterystyka ta wyraźnie pokazuje, przy jakich częstotliwościach synchroniczne i odpowiadające sobie co do wielkości zmiany mocy obserwuje się w dwóch analizowanych szeregach czasowych lub gdzie znajdują się obszary ich maksymalnych zbieżności i maksymalnych rozbieżności.
Zilustrujmy zastosowanie analizy spektralnej na przykładzie. Przeanalizujmy fale koniunktury w Europie w okresie początków rozwoju przemysłu. Do analizy wykorzystujemy niewygładzony szereg czasowy wskaźników cen pszenicy uśrednionych przez Beveridge’a na podstawie danych z 40 rynków europejskich na przestrzeni 370 lat od 1500 do 1869. Otrzymujemy widma
seria i jej poszczególne odcinki trwające 100 lat co 25 lat.
Analiza widmowa pozwala oszacować moc każdej harmonicznej w widmie. Najpotężniejsze są fale o okresie 50 lat, które, jak wiadomo, odkrył N. Kondratiew 1 i otrzymały jego imię. Analiza pozwala stwierdzić, że nie powstały one pod koniec XVII – na początku XIX wieku, jak uważa wielu ekonomistów. Powstawały w latach 1725–1775.
Konstrukcja modeli autoregresyjnych i zintegrowanych modeli średniej ruchomej ( ARIMA) są uważane za przydatne do opisywania i prognozowania stacjonarnych i niestacjonarnych szeregów czasowych, które wykazują jednolite wahania wokół zmieniającej się średniej.
Modele ARIMA są kombinacją dwóch modeli: autoregresyjnego (AR) i średnia ruchoma (średnia krocząca - MA).
Modele średniej ruchomej (MAMA) reprezentują proces stacjonarny jako liniową kombinację kolejnych wartości tzw. „białego szumu”. Modele takie okazują się przydatne zarówno jako samodzielne opisy procesów stacjonarnych, jak i jako dodatek do modeli autoregresyjnych w celu bardziej szczegółowego opisu składowej szumu.
Algorytmy obliczania parametrów modelu MAMA są bardzo wrażliwe na błędny dobór liczby parametrów dla konkretnego szeregu czasowego, szczególnie w kierunku ich wzrostu, co może skutkować brakiem zbieżności obliczeń. Zaleca się, aby na początkowych etapach analizy nie wybierać modelu średniej ruchomej z dużą liczbą parametrów.
Ocena wstępna – pierwszy etap analizy z wykorzystaniem modelu ARIMA. Proces oceny wstępnej kończy się z chwilą przyjęcia hipotezy o adekwatności modelu do szeregu czasowego lub wyczerpania dopuszczalnej liczby parametrów. W rezultacie wyniki analizy obejmują:
- wartości parametrów modelu autoregresyjnego i modelu średniej ruchomej;
- dla każdego kroku prognozy wskazana jest średnia wartość prognozy, błąd standardowy prognozy, przedział ufności prognozy dla określonego poziomu istotności;
- statystyki do oceny poziomu istotności hipotezy nieskorelowanych reszt;
- wykresy szeregów czasowych wskazujące błąd standardowy prognozy.
- Znaczna część materiałów w dziale PZ opiera się na zapisach ksiąg: Basovsky L.E. Prognozowanie i planowanie w warunkach rynkowych. - M.: INFRA-M, 2008. Gilmore R. Stosowana teoria katastrof: w 2 książkach. Książka 1/ os. z angielskiego M.: Mir, 1984.
- Jean Baptiste Joseph Fourier (Jean Baptiste Joseph Fourier; 1768-1830) – francuski matematyk i fizyk.
- Nikołaj Dmitriewicz Kondratiew (1892-1938) – ekonomista rosyjski i radziecki.
ANALIZA SZEREGÓW CZASOWYCH
WSTĘP
ROZDZIAŁ 1. ANALIZA SZEREGÓW CZASOWYCH
1.1 SZEREG CZASOWY I JEGO PODSTAWOWE ELEMENTY
1.2 AUTOKORRELACJA POZIOMÓW SZEREGÓW CZASOWYCH I IDENTYFIKACJA JEGO STRUKTURY
1.3 MODELOWANIE TRENDÓW SZEREGÓW CZASOWYCH
1.4 METODA najmniejszych kwadratów
1.5 SPROWADZENIE RÓWNANIA TRENDU DO FORMY LINIOWEJ
1.6 SZACOWANIE PARAMETRÓW RÓWNAŃ REGRESJI
1.7 ADDYTYWNE I WIELOKLIKATNE MODELE SZEREGÓW CZASOWYCH
1.8 STACJONARNE SERIE CZASOWE
1.9 ZASTOSOWANIE SZYBKIEJ TRANSFORMACJI FOURIERA DO STACJONARNEGO SZEREGOWU CZASOWEGO
1.10 AUTOKORELACJA RESZTÓW. KRYTERIUM DURBINA-WATSONA
Wstęp
Niemal w każdej dziedzinie istnieją zjawiska, które są interesujące i ważne do zbadania pod kątem ich rozwoju i zmian w czasie. W życiu codziennym interesujące mogą być na przykład warunki meteorologiczne, ceny konkretnego produktu, pewne cechy stanu zdrowia jednostki itp. Wszystko to zmienia się w czasie. Z biegiem czasu zmienia się działalność gospodarcza, tryb konkretnego procesu produkcyjnego, głębokość snu danej osoby i postrzeganie programu telewizyjnego. Reprezentuje całość pomiarów dowolnej cechy tego rodzaju w pewnym okresie czasu szereg czasowy.
Zbiór istniejących metod analizy takich serii obserwacji nazywa się Analiza szeregów czasowych.
Główną cechą odróżniającą analizę szeregów czasowych od innych typów analiz statystycznych jest znaczenie kolejności dokonywania obserwacji. Jeśli w wielu zagadnieniach obserwacje są statystycznie niezależne, to w szeregach czasowych są z reguły zależne, a charakter tej zależności można określić poprzez położenie obserwacji w ciągu. Charakter szeregu i struktura procesu generującego szereg mogą z góry określić kolejność tworzenia sekwencji.
Cel Praca polega na uzyskaniu modelu dyskretnego szeregu czasowego w dziedzinie czasu, który charakteryzuje się maksymalną prostotą i minimalną liczbą parametrów, a jednocześnie adekwatnie opisuje obserwacje.
Uzyskanie takiego modelu jest ważne z następujących powodów:
1) może pomóc zrozumieć naturę systemu generującego szeregi czasowe;
2) kontrolować proces generujący serię;
3) można go wykorzystać do optymalnego przewidywania przyszłych wartości szeregów czasowych;
Najlepiej opisać szeregi czasowe modele niestacjonarne, w którym trendy i inne pseudostabilne cechy, prawdopodobnie zmieniające się w czasie, są uważane za zjawiska statystyczne, a nie deterministyczne. Dodatkowo często zauważalne są szeregi czasowe związane z gospodarką sezonowy lub okresowe składniki; składniki te mogą zmieniać się w czasie i muszą być opisane za pomocą cyklicznych modeli statystycznych (prawdopodobnie niestacjonarnych).
Niech obserwowanymi szeregami czasowymi będą y 1 , y 2 , . . ., y n. Rozumiemy ten wpis w następujący sposób. Istnieją liczby T reprezentujące obserwację pewnej zmiennej w T równoodległych momentach czasu. Dla wygody momenty te ponumerowano liczbami całkowitymi 1, 2, . . .,T. Dość ogólnym modelem matematycznym (statystycznym lub probabilistycznym) jest model postaci:
y t = f(t) + u t, t = 1, 2, . . ., T.
W modelu tym obserwowany szereg traktowany jest jako suma pewnego ciągu całkowicie deterministycznego (f(t)), który można nazwać składową matematyczną, oraz ciągu losowego (u t ), który podlega pewnemu prawu probabilistycznemu. (Czasami w odniesieniu do tych dwóch komponentów używa się odpowiednio terminów sygnał i szum). Te składniki obserwowanego szeregu są nieobserwowalne; są to wielkości teoretyczne. Dokładne znaczenie tego rozkładu zależy nie tylko od samych danych, ale częściowo od tego, co należy rozumieć przez powtórzenie eksperymentu, z którego wynikają te dane. Stosowana jest tu tak zwana interpretacja „częstotliwościowa”. Uważa się, że przynajmniej w zasadzie można całą sytuację powtórzyć, uzyskując nowe zestawy obserwacji. Składniki losowe mogą obejmować między innymi błędy obserwacyjne.
W artykule rozpatrzono model szeregów czasowych, w którym na trend nakłada się składowa losowa, tworząc losowy proces stacjonarny. W takim modelu zakłada się, że upływ czasu nie wpływa w żaden sposób na składową losową. Mówiąc dokładniej, zakłada się, że oczekiwanie matematyczne (czyli wartość średnia) składnika losowego jest identycznie równa zeru, wariancja jest równa pewnej stałej i że wartości u t w różnych momentach są nieskorelowane. Zatem dowolna zależność od czasu jest uwzględniana w składniku systematycznym f(t). Sekwencja f(t) może zależeć od nieznanych współczynników i znanych wielkości, które zmieniają się w czasie. W tym przypadku nazywa się to „funkcją regresji”. Metody wnioskowania statystycznego dotyczące współczynników funkcji regresji okazują się przydatne w wielu obszarach statystyki. Wyjątkowość metod związanych konkretnie z szeregami czasowymi polega na tym, że badają one modele, w których wyżej wymienione wielkości zmieniające się w czasie są znanymi funkcjami t.
Rozdział 1. Analiza szeregów czasowych
1.1 Szereg czasowy i jego główne elementy
Szereg czasowy to zbiór wartości dowolnego wskaźnika dla kilku kolejnych momentów lub okresów czasu. Każdy poziom szeregu czasowego kształtuje się pod wpływem dużej liczby czynników, które można podzielić na trzy grupy:
· czynniki kształtujące trend serii;
· czynniki tworzące cykliczne wahania szeregu;
· czynniki losowe.
Przy różnych kombinacjach tych czynników w badanym procesie lub zjawisku zależność poziomów szeregu od czasu może przybierać różne formy. Po pierwsze, większość szeregów czasowych wskaźników ekonomicznych ma trend charakteryzujący długoterminowy skumulowany wpływ wielu czynników na dynamikę badanego wskaźnika. Jest oczywiste, że czynniki te rozpatrywane osobno mogą mieć wielokierunkowy wpływ na badany wskaźnik. Jednak razem tworzą one tendencję rosnącą lub malejącą.
Po drugie, badany wskaźnik może podlegać cyklicznym wahaniom. Wahania te mogą mieć charakter sezonowy, gdyż działalność wielu sektorów gospodarki i rolnictwa uzależniona jest od pory roku. Jeśli dostępne są duże ilości danych w długich okresach czasu, możliwe jest zidentyfikowanie wahań cyklicznych związanych z ogólną dynamiką szeregu czasowego.
Niektóre szeregi czasowe nie zawierają trendu ani składnika cyklicznego, a każdy kolejny poziom powstaje jako suma średniego poziomu szeregu i jakiejś (dodatniej lub ujemnej) składowej losowej.
W większości przypadków rzeczywisty poziom szeregu czasowego można przedstawić jako sumę lub iloczyn trendu, składników cyklicznych i losowych. Model, w którym szereg czasowy jest przedstawiany jako suma wymienionych składników, nazywa się model addytywny szereg czasowy. Model, w którym szereg czasowy jest przedstawiany jako iloczyn wymienionych składników, nazywa się model multiplikatywny szereg czasowy. Głównym zadaniem badania statystycznego pojedynczego szeregu czasowego jest identyfikacja i kwantyfikacja każdego z wymienionych powyżej składników w celu wykorzystania uzyskanych informacji do przewidywania przyszłych wartości szeregu.
1.2 Autokorelacja poziomów szeregów czasowych i identyfikacja jej struktury
Jeśli w szeregu czasowym występuje trend i wahania cykliczne, wartości każdego kolejnego poziomu szeregu zależą od poprzednich. Zależność korelacyjna pomiędzy kolejnymi poziomami szeregu czasowego nazywa się autokorelacja poziomów szeregów.
Można go zmierzyć ilościowo za pomocą współczynnika korelacji liniowej pomiędzy poziomami pierwotnego szeregu czasowego a poziomami tego szeregu, przesuniętymi o kilka kroków w czasie.
Jednym z roboczych wzorów obliczania współczynnika autokorelacji jest:
(1.2.1)Jako zmienną x rozważymy szereg y 2, y 3, ..., y n; jako zmienna y – szereg y 1, y 2, . . . ,y n – 1 . Wtedy powyższy wzór przyjmie postać:
(1.2.2)W podobny sposób można wyznaczyć współczynniki autokorelacji drugiego i wyższych rzędów. Zatem współczynnik autokorelacji drugiego rzędu charakteryzuje bliskość powiązania poziomów y t i y t – 1 i jest określony wzorem
(1.2.3)Liczba okresów, dla których obliczany jest współczynnik autokorelacji, nazywa się lagom. Wraz ze wzrostem opóźnienia maleje liczba par wartości, z których obliczany jest współczynnik autokorelacji. Niektórzy autorzy uważają za wskazane stosowanie reguły zapewniającej statystyczną wiarygodność współczynników autokorelacji – maksymalne opóźnienie nie powinno przekraczać (n/4).

