時系列分析手法。 要約: 時系列グラフの分析は次のことを示します
時系列分析を使用すると、時間の経過に伴うパフォーマンスを調査できます。 時系列とは、統計指標の数値を時系列に並べたものです。
このようなデータは、毎日の株価、為替レート、四半期、年間の販売量、生産など、人間の活動のさまざまな分野で一般的です。 月ごとの降水量など、気象学の典型的な時系列。
Excelの時系列
プロセスの値を一定間隔で記録すると、時系列の要素が得られます。 彼らは、変動性を規則的な要素とランダムな要素に分割しようとしています。 シリーズのメンバーの定期的な変更は、通常、予測可能です。
Excelで時系列分析をしてみましょう。 例: ある小売チェーンは、人口 50,000 人未満の都市にある店舗の商品販売データを分析します。 期間 – 2012年から2015年 課題は、主な開発傾向を特定することです。
売上データを Excel テーブルに入力してみましょう。
「データ」タブで「データ分析」ボタンをクリックします。 表示されていない場合は、メニューに移動します。 「Excelのオプション」-「アドイン」。 下部の「Go」をクリックして「Excel アドイン」に移動し、「分析パッケージ」を選択します。
「データ分析」設定の接続について詳しく説明します。
必要なボタンがリボン上に表示されます。

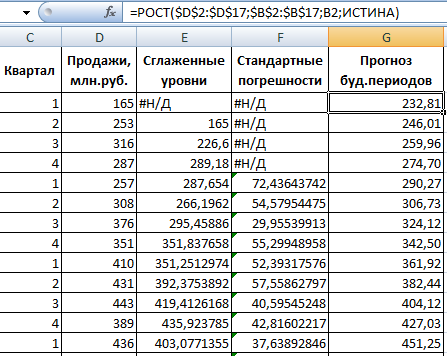
提案された統計分析ツールのリストから、「指数平滑法」を選択します。 この平準化方法は、値が大きく変動する時系列に適しています。

ダイアログボックスに記入します。 入力間隔 – 売上値の範囲。 減衰係数 – 指数平滑化係数 (デフォルト – 0.3)。 出力範囲 – 出力範囲の左上のセルへの参照。 プログラムは平滑化されたレベルをここに配置し、サイズを個別に決定します。 「グラフ出力」、「標準誤差」にチェックを入れます。

「OK」をクリックしてダイアログボックスを閉じます。 分析結果:

標準誤差を計算するために、Excel は次の式を使用します: =ROOT(SUMVARANGE('実際の値の範囲'; '予測値の範囲')/ '平滑化ウィンドウ サイズ')。 たとえば、=ROOT(SUMVARE(C3:C5,D3:D5)/3) となります。
Excel での時系列予測
前の例のデータを使用して売上予測を立ててみましょう。
実際の製品販売量を表示するグラフに傾向線を追加します (グラフの右ボタン – [傾向線を追加])。
傾向線パラメータの設定:

予測モデルの誤差を最小限に抑えるために多項式トレンドを選択します。

R2 = 0.9567、つまり、この比率は時間の経過に伴う売上の変化の 95.67% を説明します。
傾向方程式は、予測値を計算するためのモデル式です。

かなり楽観的な結果が得られます。
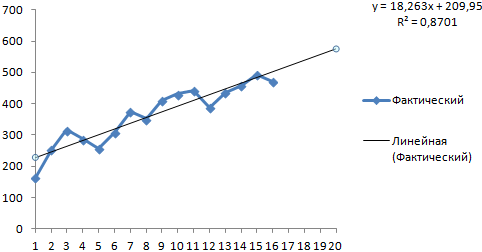
この例では、依然として指数関数的な依存性が存在します。 したがって、線形トレンドを構築する場合、より多くのエラーと不正確さが生じます。
Excel で GROWTH 関数を使用して指数関係を予測することもできます。
直線的な関係の場合 – TREND。
予測を行う場合、1 つの方法だけを使用することはできません。大きな偏差や不正確さが生じる可能性が高くなります。
時系列分析の目標。一定期間にわたる経済データに基づく時系列の実際的な研究では、計量経済学者は、この系列の特性と、この系列を生成する確率的メカニズムについて結論を導き出す必要があります。 時系列を研究する場合、ほとんどの場合、次の目標が設定されます。
1. シリーズの特徴的な機能の簡単な(圧縮された)説明。
2. 時系列を記述する統計モデルの選択。
3. 過去の観察に基づいて将来の値を予測します。
4. 時系列を生成するプロセスの制御。
実際には、これらの目標や同様の目標は常に達成できるわけではなく、完全に達成できるわけでもありません。 これは、観察時間が限られているために不十分な観察によって妨げられることがよくあります。 さらに多くの場合、時系列の統計構造は時間の経過とともに変化します。
時系列分析の段階 . 通常、時系列の実際の分析では、次の段階が順番に実行されます。
1. 一時的な rad の動作のグラフィック表示と説明。
2. 時系列の定期的な時間依存コンポーネント (トレンド、季節コンポーネント、周期コンポーネント) の特定と削除。
3. プロセスの低周波または高周波成分の分離と除去 (濾過)。
4. 上記のコンポーネントを削除した後に残る時系列のランダムなコンポーネントの研究。
5. ランダム成分を記述する数学的モデルの構築 (選択) とその妥当性の検証。
6. 時系列で表されるプロセスの将来の展開を予測します。
7. 異種間の相互作用の研究 臨時議会。
これらの問題を解決するには、さまざまな方法が多数あります。 これらのうち、最も一般的なものは次のとおりです。
8. 相関分析。これにより、1 つのプロセス内 (自己相関) または複数のプロセス間 (相互相関) の重要な周期的な依存関係とその遅れ (遅延) を特定できます。
9. スペクトル分析。時系列の周期的および準周期的成分を見つけることができます。
10. 時系列を変換して高周波または季節変動を除去するように設計された平滑化とフィルタリング。
12. 予測。一時的な rad の動作の選択されたモデルに基づいて、将来の値を予測できます。
トレンドモデル
最も単純なトレンドモデル . ここでは、経済時系列の分析や他の多くの分野で最もよく使用されるトレンド モデルを示します。 まず、単純な線形モデルです
どこ 0、1– 傾向モデル係数;
t – 時間。
時間の単位は、時間、日、週、月、四半期、または年です。 269 は、そのシンプルさにも関わらず、多くの実世界のアプリケーションで役立つことが証明されています。 トレンドの非線形性が明らかな場合は、次のモデルのいずれかが適している可能性があります。
1. 多項式:
(270)
多項式の次数はどこですか P実際の問題では、5 を超えることはほとんどありません。
2. 対数:
このモデルは、一定の増加率を維持する傾向があるデータに最もよく使用されます。
3. ロジスティクス:
 (272)
(272)
4. ゴンペルツ
![]() (273)、ここで
(273)、ここで
最後の 2 つのモデルは、S 字型のトレンド曲線を生成します。 これらは、初期段階では成長率が徐々に増加し、最後には成長率が徐々に減衰するプロセスに対応します。 このようなモデルが必要なのは、多くの経済プロセスがかなり急速な成長(または減少)のため、一定の成長率または多項式モデルに従って長期間発展することが不可能であるためです。
予測する場合、傾向は主に長期予測に使用されます。 当てはめられた傾向曲線のみに基づく短期予測の精度は通常不十分です。
最小二乗法は、時系列から傾向を推定して除去するために最もよく使用されます。 この方法については、マニュアルの 2 番目のセクションの線形回帰分析の問題で詳しく説明されています。 時系列値は応答 (従属変数) として扱われ、時刻 t– 応答に影響を与える要因として (独立変数)。
時系列は、そのメンバーの相互依存性 (少なくとも時間的にそれほど離れていない) によって特徴付けられます。これは、すべての観測値が独立していると想定される従来の回帰分析とは大きく異なります。 ただし、適切な傾向モデルが選択され、観測値に大きな外れ値がない場合、これらの条件下での傾向推定は通常合理的です。 回帰分析の制限に対する上記の違反は、推定値というよりは統計的特性に影響を与えます。 したがって、時系列の項間に重大な依存関係がある場合、残差二乗和に基づく分散推定では不正確な結果が得られます。 モデル係数などの信頼区間も正しくないことが判明します。 せいぜい、それらは非常に近似的であると考えられます。
導入
この章では、(時間の経過とともに) シーケンシャルに取得される順序付けされたデータを記述する問題について検討します。 一般に、順序付けは時間だけでなく空間でも起こります。たとえば、ねじの直径は長さの関数として (1 次元の場合)、気温の値は空間座標の関数として (3 次元の場合)、 -次元の場合)。
観測行列内の行の順序が任意である回帰分析とは異なり、時系列では順序付けが重要であるため、異なる時点での値間の関係が重要になります。
系列の値が個々の時点でわかっている場合、そのような系列は次のように呼ばれます。 離散、 とは異なり 継続的な、その値はいつでもわかります。 連続する 2 つの瞬間の間の間隔を「間隔」と呼びましょう。 タクト(ステップ)。 ここでは、カウント単位として固定クロック サイクル長を持つ離散時系列を主に考えます。 経済指標の時系列は、原則として離散的であることに注意してください。
系列の値は次のとおりです。 直接測定可能(価格、収益性、温度)、または 集計(累計)たとえば、出力ボリューム。 タイムステップ中に貨物運送業者が移動した距離。
系列の値が決定論的な数学関数によって決定される場合、その系列は次のように呼ばれます。 決定的な。 これらの値が確率モデルを使用してのみ記述できる場合、時系列は次のように呼ばれます。 ランダム.
時間の経過とともに起こる現象をこう呼ぶ プロセスしたがって、決定的プロセスまたはランダムなプロセスについて話すことができます。 後者の場合、この用語がよく使われます。 「確率過程」。 時系列の分析されたセグメントは、隠れた確率メカニズムによって生成された、研究対象の確率過程の特定の実装 (サンプル) と考えることができます。
時系列は多くの主題分野で発生し、異なる性質を持っています。 彼らの研究にはさまざまな方法が提案されており、時系列理論は非常に広範な学問となっています。 したがって、時系列の種類に応じて、時系列分析理論の次のセクションを区別できます。
– 確率的特性が時間の経過とともに変化しない確率変数のシーケンスを記述する定常ランダムプロセス。 同様のプロセスは、無線工学、気象学、地震学などの分野で広く行われています。
– 液体と気体の相互浸透中に起こる拡散プロセス。
– サービス要求の受信、自然災害、人為的災害など、一連のイベントを記述するポイントプロセス。 同様のプロセスがキュー理論でも研究されています。
経済学や金融における実際的な問題の解決に役立つ、時系列分析の応用的な側面を考察することに限定します。 主に、時系列を記述し、その動作を予測するための数学的モデルを選択する方法に重点が置かれます。
1.時系列分析の目標、方法、段階
時系列の実際的な研究には、時系列の特性を特定し、この時系列を生成する確率的メカニズムについて結論を引き出すことが含まれます。 時系列を研究する主な目的は次のとおりです。
– シリーズの特徴を凝縮した形で説明。
– 時系列モデルの構築。
– 過去の観察に基づいた将来の価値の予測;
– 差し迫った有害事象を警告する信号をサンプリングすることにより、時系列を生成するプロセスの制御。
初期データの欠如 (不十分な観察期間) と時間の経過に伴う系列の統計構造の変動の両方により、設定された目標を達成することが常に可能であるとは限りません。
リストされた目標は、時系列分析の段階の順序を大部分決定します。
1) シリーズの動作のグラフィック表示と説明。
2) 時間に依存する系列の規則的で非ランダムな成分の特定と除外。
3)規則的な成分を除去した後に残る時系列のランダムな成分の研究。
4)ランダム成分を記述する数学的モデルの構築(選択)とその適切性のチェック。
5) シリーズの将来の値を予測します。
時系列を分析する場合、さまざまな方法が使用されますが、最も一般的な方法は次のとおりです。
1) シリーズの特徴(周期性、傾向など)を特定するために使用される相関分析。
2) スペクトル分析。時系列の周期成分を見つけることができます。
3) 時系列を変換して高周波および季節変動を除去するように設計された平滑化およびフィルタリング手法。
5)予測方法。
2. 時系列の構成要素
すでに述べたように、時系列モデルでは、決定的コンポーネントとランダムなコンポーネントの 2 つの主なコンポーネントを区別するのが通例です (図)。 時系列の決定論的要素の下で
数値シーケンスを理解します。その要素は時間の関数として特定の規則に従って計算されます。 t。 データから決定論的成分を除外することで、ゼロ付近で振動する系列が得られます。これは、極端な場合には純粋にランダムなジャンプを表すことができ、別の極端な場合には滑らかな振動運動を表すことができます。 ほとんどの場合、その中間には、不規則性と系列の連続する項の依存性による体系的な効果が存在します。さらに、決定的コンポーネントには次の構造コンポーネントが含まれる場合があります。
1) トレンド g。これは時間の経過に伴うプロセスの滑らかな変化であり、長期的な要因の作用によって引き起こされます。 経済学におけるそのような要因の例としては、次のものが挙げられます。 a) 人口の人口統計的特徴(数、年齢構成)の変化。 b) 技術的および経済的発展。 c) 消費の増加。
2) 季節の影響 s, あらかじめ決められた頻度で周期的に作用する因子の存在に関連しています。 この場合のシリーズには階層的な時間スケールがあり (たとえば、1 年の中に季節、四半期、月に関連付けられた季節があります)、同様の効果がシリーズ内の同じ時点で発生します。
米。 時系列の構造コンポーネント。
季節的影響の典型的な例: 日中の高速道路の混雑状況、曜日別、季節別、8 月下旬から 9 月上旬の学童向け商品のピーク販売など。 季節成分は時間の経過とともに変化することもあれば、変動する性質のものであることもあります。 したがって、旅客機による交通量のグラフ (図を参照) では、イースター休暇中に発生する局所的なピークが、タイミングのばらつきにより「浮いている」ことがわかります。
周期成分 c、相対的な上昇と下降の長い期間を表し、可変の持続時間と振幅のサイクルで構成されます。 同様の構成要素は、多くのマクロ経済指標に非常に典型的です。 ここでの周期的変化は、需要と供給の相互作用のほか、資源の枯渇、気象条件、税制の変更などの要因によって引き起こされます。周期的要素を正式な方法で特定するのは非常に困難であることに注意してください。研究対象のシリーズのデータのみに基づいています。
「爆発物」コンポーネント 私そうでない場合は、時系列に対する重大な短期的な影響として理解される介入。 介入の一例は、ドル為替レートが1日あたり数十パーセント上昇した1994年の「暗黒の火曜日」の出来事である。
系列のランダム成分は、ランダムな性質の多数の要因の影響を反映しており、「ホワイト ノイズ」の形で最も単純なものから、自己回帰移動平均モデルで記述される非常に複雑なものまで、さまざまな構造を持つことができます (詳細はこちら)下に)。
構造コンポーネントを特定した後、時系列でのそれらの出現形式を特定する必要があります。 表現の最上位レベルでは、決定論的およびランダムなコンポーネントのみを強調表示し、加算または乗法モデルが通常使用されます。
加法モデルの形式は次のとおりです。
;乗法 –
時系列分析の種類と手法
時系列は、等時間間隔で取得された変数の連続した測定値の集合です。 時系列分析を使用すると、次の問題を解決できます。
- 時系列の構造を調査します。これには、原則として、平均レベルの規則的な変化やランダムな周期的変動などの傾向が含まれます。
- 時系列間の相関関係として現れる、一連の変化を決定するプロセス間の因果関係を調査します。
- 時系列で表されるプロセスの数学的モデルを構築します。
- スムージング ツールとフィルタリング ツールを使用して時系列を変換します。
- プロセスの将来の展開を予測します。
既知の方法の重要な部分は定常プロセスの分析を目的としており、その統計的特性は平均値と分散による正規分布によって特徴付けられ、一定で時間の経過とともに変化しません。
しかし、このシリーズには固定されていないキャラクターが登場することがよくあります。 非定常性は次のように除去できます。
- トレンドを差し引きます。つまり、 平均値の変化。回帰分析によって選択できる決定論的な関数で表されます。
- 特殊な非定常フィルタを使用してフィルタリングを実行します。
時系列を標準化して手法を統一する
分析の際には、平均値で割ることにより一般的または季節的なセンタリングを実行するとともに、標準偏差で割ることにより正規化を実行することをお勧めします。
シリーズを中心に配置すると、スペクトル分析などで結果の解釈が困難になる可能性がある非ゼロ平均が削除されます。 正規化の目的は、計算精度の低下につながる可能性のある、計算における大きな数値を伴う演算を回避することです。
時系列のこれらの予備的な変換の後、その数学的モデルを構築でき、それに応じて予測が実行されます。 時系列のある程度の継続が得られました。
予測結果を元のデータと比較するには、実行された変換とは逆の変換をそのデータに対して実行する必要があります。
実際には、モデリングと予測の方法が最もよく使用され、相関とスペクトル分析は補助的な方法として考慮されます。 それは妄想です。 平均的な傾向の展開を予測する方法では、重大な誤差を伴う推定値を取得することが可能になるため、時系列で表される変数の将来の値を予測することが非常に困難になります。
相関およびスペクトル分析の方法により、研究対象のプロセスが進行しているシステムの慣性を含むさまざまな特性を特定することが可能になります。 これらの方法を使用すると、現在のプロセスのダイナミクスから、既知のダイナミクスが将来のプロセスの開発にどのように、どの程度の遅延で影響するかを十分な信頼性を持って判断することが可能になります。 長期的な予測の場合、この種の分析は貴重な結果をもたらします。
傾向分析と予測
傾向分析は、傾向の数学的モデルを構築して時系列の平均値の変化を調査し、これに基づいて系列の将来の値を予測することを目的としています。 傾向分析は、単純な線形回帰モデルまたは非線形回帰モデルを構築することによって実行されます。
使用される初期データは 2 つの変数で、1 つは時間パラメーターの値、もう 1 つは時系列の実際の値です。 分析プロセス中に、次のことができます。
- いくつかの数学的傾向モデルをテストし、系列のダイナミクスをより正確に記述するモデルを選択します。
- 特定の信頼確率を備えた選択された傾向モデルに基づいて、時系列の将来の動作の予測を構築します。
- 相関およびスペクトル分析に必要な定常性を確保するために時系列から傾向を削除します。このため、回帰モデルを計算した後、分析を実行するために残差を保存する必要があります。
さまざまな機能や組み合わせがトレンドモデルとして使用され、べき級数と呼ばれることもあります。 多項式モデル。最大の精度はフーリエ級数の形式のモデルによって提供されますが、そのようなモデルを使用できる統計パッケージは多くありません。
シリーズトレンドモデルの導出を説明しましょう。 1929 年から 1978 年までの米国の国民総生産に関する一連のデータを使用します。 現在の価格で。 多項式回帰モデルを構築してみましょう。 モデルの精度は、多項式の次数が 5 番目に達するまで増加しました。
Y = 145.6 - 35.67* + 4.59* 2 - 0.189* 3 + 0.00353x 4 + 0.000024* 5、
(14,9) (5,73) (0,68) (0,033) (0,00072) (0,0000056)
どこ う - GNP、10億ドル。
* - 初年度の 1929 年から数えた年数。
係数の下は標準誤差です。
モデル係数の標準誤差は小さく、モデル係数の値の半分に等しい値に達していません。 これはモデルの品質が良いことを示しています。
モデルの決定係数は、縮小された重相関係数の 2 乗に等しく、99% でした。 これは、モデルがデータの 99% を説明していることを意味します。 モデルの標準誤差は 147 億であることが判明し、帰無仮説 (関連性がない仮説) の有意水準は 0.1% 未満でした。
結果のモデルを使用すると、実際のデータと比較した予測を行うことができます。それを表に示します。 PZ. 1.
米国のGNPの予測と実際の規模、10億ドル。
テーブル PZ.1
表に示されているデータから明らかなように、多項式モデルを使用して得られた予測はあまり正確ではありません。
相関分析
相関分析は、相関とその遅れ、つまり周期性の遅れを特定するために必要です。 1つのプロセス内での通信を 自己相関、そしてシリーズによって特徴付けられる 2 つのプロセス間の接続 - 相互相関。高いレベルの相関関係は、因果関係、つまり 1 つのプロセス内または 2 つのプロセス間の相互作用の指標として機能し、ラグ値は相互作用の伝達における時間遅延を示します。
通常、相関関数の値を計算するプロセスでは、 に番目のステップでは、セグメントの長さに沿った変数間の相関関係 / = 1,...,を計算します。 (p - k)最初の行 バツそしてセグメント / = に,..., P 2 行目 K したがって、セグメントの長さが変化します。
結果は、パラメトリック相関係数を彷彿とさせる、実際の解釈が難しい値ですが、それと同一ではありません。 したがって、多くの統計パッケージで使用される相関分析の可能性は、狭い範囲の時系列クラスに限定されており、これはほとんどの経済プロセスでは一般的ではありません。
相関分析の経済学者は、あるプロセスから別のプロセスへの影響の伝達の遅れや、同じプロセスのその後の発展に対する初期の撹乱の影響を研究することに興味を持っています。 このような問題を解決するために、既知の方法の修正と呼ばれる方法が提案されました。 間隔相関".
クライチェフ A.P. Windows 環境でのデータ分析の方法とツール。 - M.: 情報学とコンピュータ、2003 年。
間隔相関関数は、指定されたサイズと位置の最初の行の固定セグメントと、系列の先頭から連続的にシフトして選択された 2 番目の行の同じサイズのセグメントの間で計算された一連の相関係数です。
2 つの新しいパラメーターが定義に追加されます。系列のシフトされたフラグメントの長さとその初期位置です。また、数学的統計で受け入れられているピアソン相関係数の定義も使用されます。 これにより、計算された値が比較可能になり、解釈が容易になります。
通常、分析を実行するには、自己相関分析または相互相関分析用に 1 つまたは 2 つの変数を選択し、次のパラメーターも設定する必要があります。
マッチング用に分析された系列の時間ステップの次元
結果は実際のタイムラインで表示されます。
最初の行のシフトされたフラグメントの長さ。
シリーズの要素の。
行の先頭に対するこのフラグメントのシフト。
もちろん、区間相関または別の相関関数のオプションを選択する必要があります。
分析用に 1 つの変数が選択された場合、連続的に増加するラグに対して自己相関関数の値が計算されます。 自己相関関数を使用すると、特定のフラグメント内の変化のダイナミクスが、時間的にシフトされた独自のセグメントでどの程度再現されるかを判断できます。
分析用に 2 つの変数が選択された場合、相互相関関数の値は、最初の変数に対する選択された変数の 2 番目の変数のシフトである連続的に増加するラグに対して計算されます。 相互相関関数を使用すると、最初の行のフラグメントの変化が時間的にシフトされた 2 番目の行のフラグメントでどの程度再現されるかを判断できます。
分析の結果には、相関係数の臨界値の推定値が含まれている必要があります。 g0仮説のために 「r0= 0」は、特定の有意水準で表されます。 これにより、統計的に重要でない相関係数を無視できます。 遅れを示す相関関数の値を取得する必要があります。 自己相関関数または相互相関関数のグラフは非常に便利で視覚的です。
例を挙げて相互相関分析の使用法を説明しましょう。 1930年から1979年までの60年間にわたるアメリカとソ連のGNP成長率の関係を評価してみましょう。 長期的な傾向の特徴を取得するために、シリーズのシフトされた断片は 25 年間の長さが選択されました。 その結果、異なるラグの相関係数が得られました。
相関関係が有意であることが判明する唯一の遅れは 28 年です。 この遅れでの相関係数は 0.67 ですが、しきい値、最小値は 0.36 です。 28年遅れのソ連経済の長期発展の循環性は、米国経済の長期発展の循環性と密接に関係していたことが判明した。
スペクトル分析
定常時系列の構造を解析する一般的な方法は、離散フーリエ変換を使用して時系列のスペクトル密度またはスペクトルを推定することです。 この方法は次のように使用できます。
- 1 つの時系列の記述統計、または 2 つの時系列間の依存関係の記述統計を取得します。
- 系列の周期的および準周期的特性を識別するため。
- 他の方法で構築されたモデルの適切性をチェックするため。
- 圧縮データの表示用。
- 時系列のダイナミクスを補間します。
スペクトル分析推定の精度は、スムージング ウィンドウと平均化手法などの特別な方法を使用することによって高めることができます。
分析するには、1 つまたは 2 つの変数を選択し、次のパラメーターを指定する必要があります。
- 結果をリアルタイムおよび周波数スケールと調整するために必要な、分析された系列の時間ステップの次元。
- 長さ に時系列の分析されたセグメント (それに含まれるデータの数の形式)。
- 行の次のセグメントのシフト 0まで前のものとの相対。
- いわゆる平滑化時間ウィンドウのタイプ 漏電の影響;
- 時系列の連続するセグメントにわたって計算される周波数特性の平均化の一種。
分析の結果には、スペクトログラム、つまり振幅-周波数スペクトル特性の値と位相-周波数特性の値が含まれます。 クロススペクトル解析の場合、結果は伝達関数とスペクトルコヒーレンス関数の値でもあります。 分析結果にはピリオドグラム データも含まれる場合があります。
クロススペクトルの振幅-周波数特性は、クロススペクトル密度とも呼ばれ、2 つの相互接続されたプロセスの相互スペクトルの振幅の周波数依存性を表します。 この特性は、解析された 2 つの時系列において、どの周波数で同期し、大きさが対応するパワー変化が観察されるか、またはそれらの最大一致領域と最大不一致領域がどこに位置するかを明確に示します。
例を挙げてスペクトル分析の使用法を説明しましょう。 産業発展初期のヨーロッパの経済情勢の波を分析してみましょう。 分析には、1500 年から 1869 年までの 370 年間にわたる欧州 40 市場のデータに基づいて Beveridge が平均した小麦価格指数の平滑化されていない時系列を使用します。スペクトルを取得します。
シリーズとその個々のセグメントは 25 年ごとに 100 年間続きます。
スペクトル解析を使用すると、スペクトル内の各高調波のパワーを推定できます。 最も強力なのは50年の周期を持つ波で、知られているように、N.コンドラチェフ1号によって発見され、彼の名前が付けられました。 この分析により、多くの経済学者が信じているように、それらが17世紀末から19世紀初頭に形成されたものではないことが証明された。 彼らは 1725 年から 1775 年にかけて結成されました。
自己回帰および統合移動平均モデルの構築 ( 有馬)は、変化する平均値の周囲で一様な変動を示す定常時系列と非定常時系列を記述および予測するのに役立つと考えられています。
モデル 有馬 2 つのモデルの組み合わせです: 自己回帰 (AR)そして移動平均線 (移動平均 - MA)。
移動平均モデル (MA)いわゆる「ホワイトノイズ」の連続する値の線形結合として定常プロセスを表します。 このようなモデルは、定常プロセスの独立した記述として、またノイズ成分をより詳細に記述するための自己回帰モデルへの追加としての両方で有用であることが判明しています。
モデルパラメータを計算するためのアルゴリズム マ特定の時系列のパラメータ数の誤った選択、特にパラメータの増加方向の選択に非常に敏感であり、計算の収束が不足する可能性があります。 分析の初期段階では、パラメータの数が多い移動平均モデルを選択しないことをお勧めします。
予備評価 - モデルを使用した分析の第 1 段階 有馬。予備評価プロセスは、時系列に対するモデルの適切性に関する仮説が受け入れられるか、許容されるパラメータ数がなくなると終了します。 その結果、分析結果には次のものが含まれます。
- 自己回帰モデルおよび移動平均モデルのパラメータの値。
- 各予測ステップについて、平均予測値、予測の標準誤差、特定の有意レベルに対する予測の信頼区間が示されます。
- 無相関残差の仮説の有意水準を評価するための統計。
- 予測の標準誤差を示す時系列プロット。
- PZ セクションの資料の大部分は、書籍の規定に基づいています。 バソフスキー L.E.市場状況の予測と計画。 - M.: INFRA-M、2008 年。 ギルモア R.災害の応用理論: 2 冊。 本 1/あたり 英語から マ:ミール、1984年。
- ジャン・バティスト・ジョゼフ・フーリエ (ジャン・バティスト・ジョゼフ・フーリエ); 1768-1830) - フランスの数学者および物理学者。
- ニコライ・ドミトリエヴィチ・コンドラチェフ (1892-1938) - ロシアとソビエトの経済学者。
時系列分析
導入
第1章 時系列分析
1.1 時系列とその基本要素
1.2 時系列レベルの自己相関とその構造の特定
1.3 時系列トレンドモデリング
1.4 最小二乗法
1.5 トレンド方程式を線形形式に縮小する
1.6 回帰式パラメータの推定
1.7 加算時系列モデルと乗算時系列モデル
1.8 定常時系列
1.9 高速フーリエ変換を定常時系列に適用する
1.10 残差の自己相関。 ダービン・ワトソン基準
導入
ほぼすべての分野には、時間の経過とともにその発展と変化を研究する上で興味深く重要な現象が存在します。 たとえば、日常生活では、気象条件、特定の製品の価格、個人の健康状態の特定の特徴などが重要になる可能性がありますが、それらはすべて時間の経過とともに変化します。 時間の経過とともに、ビジネス活動、特定の制作プロセスのモード、人の睡眠の深さ、テレビ番組の認識が変化します。 一定期間にわたるこの種の 1 つの特性の測定値の合計は、次のことを表します。 時系列。
このような一連の観測を分析するための既存の手法のセットは、 時系列分析。
時系列分析を他のタイプの統計分析と区別する主な特徴は、観察が行われる順序が重要であることです。 多くの問題で観測値が統計的に独立している場合、時系列では原則として観測値は依存しており、この依存関係の性質はシーケンス内の観測値の位置によって決定できます。 系列の性質と系列を生成するプロセスの構造によって、系列が形成される順序が事前に決定される場合があります。
目標この作業は、時間領域における離散時系列のモデルを取得することで構成されます。このモデルは、最大限の単純性と最小限のパラメータ数を備え、同時に観測を適切に記述します。
このようなモデルを取得することは、次の理由から重要です。
1) 時系列を生成するシステムの性質を理解するのに役立ちます。
2) シリーズを生成するプロセスを制御します。
3) 時系列の将来の値を最適に予測するために使用できます。
時系列を最もよく説明する 非定常モデル、この場合、時間の経過とともに変化する可能性のある傾向やその他の疑似安定特性は、決定論的現象ではなく統計的現象と見なされます。 さらに、経済に関連する時系列では、多くの場合、顕著な変化が見られます。 季節限定、または周期的なコンポーネント。 これらのコンポーネントは時間の経過とともに変化する可能性があるため、周期的な統計 (おそらく非定常) モデルで記述する必要があります。
観測された時系列を y 1 、 y 2 、... とする。 。 ., y n . このエントリを次のように理解します。 T 個の等距離瞬間における何らかの変数の観測値を表す T 個の数値があります。 便宜上、これらの瞬間には整数 1、2、... の番号が付けられます。 。 .,T. かなり一般的な数学 (統計的または確率的) モデルは、次の形式のモデルです。
y t = f(t) + u t 、t = 1、2、... 。 .、T.
このモデルでは、観測された系列は、数学的コンポーネントと呼ぶことができる完全に決定的なシーケンス (f(t)) と、何らかの確率法則に従うランダム シーケンス (u t ) の合計として考慮されます。 (また、これら 2 つのコンポーネントに対してそれぞれ信号とノイズという用語が使用されることもあります)。 観測された系列のこれらのコンポーネントは観測できません。 それらは理論上の量です。 この分解の正確な意味は、データそのものだけでなく、これらのデータが結果として得られた実験の繰り返しが何を意味するかにも部分的に依存します。 ここでは、いわゆる「周波数」解釈が使用されます。 少なくとも原理的には、状況全体を繰り返して新しい一連の観察を取得することが可能であると考えられています。 ランダムな成分には、とりわけ観測誤差が含まれる可能性があります。
この論文では、トレンドにランダムな成分が重畳され、ランダムな定常プロセスを形成する時系列モデルを検討します。 このようなモデルでは、時間の経過はランダム成分にいかなる影響も及ぼさないと想定されます。 より正確には、ランダム成分の数学的期待値 (つまり、平均値) は全くゼロに等しく、分散はある定数に等しく、異なる時点での u t の値には相関がないと仮定されます。 したがって、系統成分 f(t) には時間依存性がすべて含まれます。 シーケンス f(t) は、いくつかの未知の係数と時間の経過とともに変化する既知の量に依存する可能性があります。 この場合の関数を「回帰関数」と呼びます。 回帰関数係数の統計的推論方法は、統計の多くの分野で役立つことが証明されています。 特に時系列に関連する方法の独自性は、時間の経過とともに変化する上記の量が t の既知の関数であるモデルを研究することです。
第1章。 時系列分析
1.1 時系列とその主な要素
時系列とは、連続するいくつかの瞬間または期間におけるインジケーターの値の集合です。 時系列の各レベルは、多数の要因の影響下で形成されます。これらの要因は、次の 3 つのグループに分類できます。
· シリーズの傾向を形成する要因。
· 系列内で周期的な変動を形成する要因。
· ランダム要素。
研究中のプロセスまたは現象におけるこれらの要因のさまざまな組み合わせにより、時間に対する系列のレベルの依存性はさまざまな形をとる可能性があります。 まず最初に、経済指標のほとんどの時系列には、調査対象の指標のダイナミクスに対する多くの要因の長期的な累積的影響を特徴付ける傾向があります。 これらの要因を個別に考慮すると、研究対象の指標に多方向の影響を与える可能性があることは明らかです。 ただし、それらは一緒になって増加または減少の傾向を形成します。
第二に、研究中の指標は周期的な変動の影響を受ける可能性があります。 多くの経済部門および農業部門の活動は時期に依存するため、これらの変動は季節的なものである可能性があります。 長期間にわたって大量のデータが利用できる場合、時系列全体のダイナミクスに関連する周期的な変動を特定することが可能です。
一部の時系列にはトレンドや周期的な要素が含まれておらず、後続の各レベルは、系列の平均レベルと何らかの (正または負の) ランダムな要素の合計として形成されます。
ほとんどの場合、時系列の実際のレベルは、トレンド、周期的、ランダムな要素の合計または積として表すことができます。 時系列がリストされたコンポーネントの合計として表されるモデルは、と呼ばれます。 加算モデル時系列。 時系列がリストされたコンポーネントの積として表現されるモデルは、と呼ばれます。 乗法モデル時系列。 個々の時系列の統計的研究の主なタスクは、取得した情報を使用して時系列の将来の値を予測するために、上記にリストされた各構成要素を特定して定量化することです。
1.2 時系列レベルの自己相関とその構造の特定
時系列に傾向や周期的な変動がある場合、時系列の後続の各レベルの値は前のレベルに依存します。 時系列の連続するレベル間の相関依存性は次のように呼ばれます。 系列レベルの自己相関.
これは、元の時系列のレベルと、時間内で数ステップずつシフトされたこの系列のレベルとの間の線形相関係数を使用して定量的に測定できます。
自己相関係数を計算するための実際の公式の 1 つは次のとおりです。
(1.2.1)変数 x として、系列 y 2、y 3、...、y n を考えます。 変数 y として - 系列 y 1、y 2、... 。 。 ,y n – 1 。 上記の式は次の形式になります。
(1.2.2)同様に、2 次以降の自己相関係数も求めることができます。 したがって、2 次の自己相関係数は、レベル y t と y t – 1 の間の関係の近さを特徴付け、次の式で決定されます。
(1.2.3)自己相関係数が計算される期間の数は と呼ばれます。 ラゴム。 ラグが増加すると、自己相関係数が計算される値のペアの数が減少します。 著者の中には、自己相関係数の統計的信頼性を確保するためにこのルールを使用することが賢明であると考える人もいます。つまり、最大ラグは (n/4) を超えてはなりません。


