Таблица значений распределения хи квадрат. Контрольная работа: Распределение "хи-квадрат" и его применение
В том случае, если полученное значение критерия χ 2 больше критического, делаем вывод о наличии статистической взаимосвязи между изучаемым фактором риска и исходом при соответствующем уровне значимости.
Пример расчета критерия хи-квадрат Пирсона
Определим статистическую значимость влияния фактора курения на частоту случаев артериальной гипертонии по рассмотренной выше таблице:
1. Рассчитываем ожидаемые значения для каждой ячейки:
2. Находим значение критерия хи-квадрат Пирсона:
χ 2 = (40-33.6) 2 /33.6 + (30-36.4) 2 /36.4 + (32-38.4) 2 /38.4 + (48-41.6) 2 /41.6 = 4.396.
3. Число степеней свободы f = (2-1)*(2-1) = 1. Находим по таблице критическое значение критерия хи-квадрат Пирсона, которое при уровне значимости p=0.05 и числе степеней свободы 1 составляет 3.841.
4. Сравниваем полученное значение критерия хи-квадрат с критическим: 4.396 > 3.841, следовательно зависимость частоты случаев артериальной гипертонии от наличия курения - статистически значима. Уровень значимости данной взаимосвязи соответствует p<0.05.
Также критерий хи-квадрат Пирсона вычисляется по формуле
Но для таблицы 2х2 более точные результаты дает критерий с поправкой Йетса

Если  то Н(0)
принимается,
то Н(0)
принимается,
В случае ![]() принимается Н(1)
принимается Н(1)
Когда число наблюдений невелико и в клетках таблицы встречается частота меньше 5, критерий хи-квадрат неприменим и для проверки гипотез используется точный критерий Фишера . Процедура вычисления этого критерия достаточно трудоемка и в этом случае лучше воспользоваться компьютерными программами статанализа.
По таблице сопряженности можно вычислить меру связи между двумя качественными признаками – ею является коэффициент ассоциации Юла Q (аналог коэффициента корреляции)

Q лежит в пределах от 0 до 1. Близкий к единице коэффициент свидетельствует о сильной связи между признаками. При равенстве его нулю – связь отсутствует.
Аналогично используется коэффициент фи-квадрат (φ 2)
ЗАДАЧА-ЭТАЛОН
В таблице описывается связь между частотой мутации у групп дрозофил с подкормкой и без подкормки
Анализ таблицы сопряженности
Для анализа таблицы сопряженности выдвигается Н 0 - гипотеза.т.е.отсуствие влияния изучаемого признака на результат исследования.Для этого рассчитывается ожидаемая частота,и строится таблица ожидания.
Таблица ожидания
| группы | Чило культур | Всего | ||||
| Давшие мутации | Не давшие мутации | |||||
| Фактическая частота | Ожидаемая частота | Фактическая частота | Ожидаемая частота | |||
| С подкормкой | ||||||
| Без подкормкой | ||||||
| всего | ||||||
Метод №1
Определяем частоту ожидания:
2756 – Х ![]() ;
;
2. 3561 – 3124
Если число наблюдении в группах мало, при применении Х 2, в случае сопоставления фактических и ожидаемых частот при дискретных распределениях сопряжено с некоторой неточностью.Для уменьшения неточности применяют поправку Йейтса.
Статистические критерии для таблиц сопряженности - Тест хи-квадрат
Чтобы получить статистические критерии для таблиц сопряженности, щелкните на кнопке Statistics... (Статистика) в диалоговом окне Crosstabs. Откроется диалоговое окно Crosstabs: Statistics (Таблицы сопряженности: Статистика) (см. рис. 11.9).
Рис. 11.9:
Флажки в этом диалоговом окне позволяют выбрать один или несколько критериев.
Тест хи-квадрат (X 2)
Корреляции
Меры связанности для переменных, относящихся к номинальной шкале
Меры связанности для переменных, относящихся к порядковой шкале
Меры связанности для переменных, относящихся к интервальной шкале
Коэффициент каппа (к )
Мера риска
Тест Мак-Немара
Статистики Кохрана и Мантеля-Хэнзеля
Эти критерии рассматриваются в двух последующих разделах, причем из-за того, что критерий хи-квадрат имеет большое значение в статистических вычислениях, ему посвящен отдельный раздел.
Тест хи-квадрат (X 2)
При проведении теста хи-квадрат проверяется взаимная независимость двух переменных таблицы сопряженности и благодаря этому косвенно выясняется зависимость обоих переменных. Две переменные считаются взаимно независимыми, если наблюдаемые частоты (f о) в ячейках совпадают с ожидаемыми частотами (f e).
Для того, чтобы провести тест хи-квадрат с помощью SPSS, выполните следующие действия:
Выберите в меню команды Analyze (Анализ) Descriptive Statistics (Дескриптивные статистики) Crosstabs... (Таблицы сопряженности)
Кнопкой Reset (Сброс) удалите возможные настройки.
Перенесите переменную sex в список строк, а переменную psyche - в список столбцов.
Щелкните на кнопке Cells... (Ячейки). В диалоговом окне установите, кроме предлагаемого по умолчанию флажка Observed, еще флажки Expected и Standardized. Подтвердите выбор кнопкой Continue.
Щелкните на кнопке Statistics... (Статистика). Откроется описанное выше диалоговое окно Crosstabs: Statistics.
Установите флажок Chi-square (Хи-квадрат). Щелкните на кнопке Continue, а в главном диалоговом окне - на ОК.
Вы получите следующую таблицу сопряженности.
Пол * Психическое состояние Таблица сопряженности
| Психическое состояние | Total | ||||||
| Крайне неустойчивое | Неустойчивое | Устойчивое | Очень устойчивое | ||||
| Пол | Женский | Count | 16 | 18 | 9 | 1 | 44 |
| Expected Count | 7,9 | 16,6 | 17,0 | 2,5 | 44,0 | ||
| Std. Residual | 2,9 | ,3 | -1,9 | -.9 | |||
| Мужской | Count | 3 | 22 | 32 | 5 | 62 | |
| Expected Count | 11,1 | 23,4 | 24,0 | 3,5 | 62,0 | ||
| Std. Residual | -2,4 | -,3 | 1,6 | ,8 | |||
| Total | Count | 19 | 40 | 41 | 6 | 106 | |
| Expected Count | 19,0 | 40,0 | 41,0 | 6,0 | 106,0 | ||
Кроме того, в окне просмотра будут показаны результаты теста хи-квадрат:
Chi-Square Tests (Тесты хи-квадрат)
| Value (Значение) | df | Asymp. Sig. (2-sided) (Асимптотическая значимость (двусторонняя)) |
|
| Pearson Chi-Square (Хи-квадрат по Пирсону) |
22,455 (а) | 3 | ,000 |
| Likelihood Ratio (Отношение правдоподобия) |
23,688 | 3 | ,000 |
| Linear-by-Linear Association (Зависимость линейный-линейный) |
20,391 | 1 | ,000 |
| N of Valid Cases (Кол-во допустимых случаев) |
106 |
а. 2 cells (25,0%) have expected count less than 5. The minimum expected count is 2,49 (2 ячейки (25%) имеют ожидаемую частоту менее 5. Минимальная ожидаемая частота 2,49.)
Для вычисления критерия хи-квадрат применяются три различных подхода:
- формула Пирсона ;
- поправка на правдоподобие ;
- тест Мантеля-Хэнзеля .
- Если таблица сопряженности имеет четыре поля (таблица 2 x 2) и ожидаемая вероятность менее 5, дополнительно выполняется точный тест Фишера .
Обычно для вычисления критерия хи-квадрат используется формула Пирсона:

Здесь вычисляется сумма квадратов стандартизованных остатков по всем полям таблицы сопряженности. Поэтому поля с более высоким стандартизованным остатком вносят более весомый вклад в численное значение критерия хи-квадрат и, следовательно, - в значимый результат. Согласно правилу, приведенному в разделе 8.9 , стандартизованный остаток 2 (1,96) или более указывает на значимое расхождение между наблюдаемой и ожидаемой частотами в той или ячейке таблицы.
В рассматриваемом примере формула Пирсона дает максимально значимую величину критерия хи-квадрат (р<0,0001). Если рассмотреть стандартизованные остатки в отдельных полях таблицы сопряженности, то на основе вышеприведенного правила можно сделать вывод, что эта значимость в основном определяется полями, в которых переменная psyche имеет значение "крайне неустойчивое". У женщин это значение сильно повышено, а у мужчин - понижено.
Корректность проведения теста хи-квадрат определяется двумя условиями:
- ожидаемые частоты < 5 должны встречаться не более чем в 20% полей таблицы;
- суммы по строкам и столбцам всегда должны быть больше нуля.
Однако в рассматриваемом примере это условие выполняется не полностью. Как указывает примечание после таблицы теста хи-квадрат, 25% полей имеют ожидаемую частоту менее 5. Однако, так как допустимый предел в 20% превышен лишь ненамного и эти поля, вследствие своего очень малого стандартизованного остатка, вносят весьма незначительную долю в величину критерия хи-квадрат, это нарушение можно считать несущественным.
Альтернативой формуле Пирсона для вычисления критерия хи-квадрат является поправка на правдоподобие:

При большом объеме выборки формула Пирсона и подправленная формула дают очень близкие результаты. В нашем примере критерий хи-квадрат с поправкой на правдоподобие составляет 23,688.
В настоящей заметке χ 2 -распределение используется для проверки согласованности набора данных с фиксированным распределением вероятностей. В критерии согласия часто ты, принадлежащие определенной категории, сравниваются с частотами, которые являются теоретически ожидаемыми, если бы данные действительно имели указанное распределение.
Проверка с помощью критерия согласия χ 2 выполняется в несколько этапов. Во-первых, определяется конкретное распределение вероятностей, которое сравнивается с исходными данными. Во-вторых, выдвигается гипотеза о параметрах выбранного распределения вероятностей (например, о ее математическом ожидании) или проводится их оценка. В-третьих, на основе теоретического распределения определяется теоретическая вероятность, соответствующая каждой категории. В заключение, для проверки согласованности данных и распределения применяется тестовая χ 2 -статистика:
где f 0 - наблюдаемая частота, f е - теоретическая, или ожидаемая частота, k - количество категорий, оставшихся после объединения, р - количество оцениваемых параметров.
Скачать заметку в формате или , примеры в формате
Использование χ 2 -критерия согласия для распределения Пуассона

Для расчета по этой формуле в Excel удобно воспользоваться функцией =СУММПРОИЗВ() (рис. 1).
Для оценки параметра λ можно воспользоваться оценкой . Теоретическую частоту X успехов (Х = 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 и более), соответствующую параметру λ = 2,9 можно определить с помощью функции =ПУАССОН.РАСП(Х;;ЛОЖЬ). Умножив пуассоновскую вероятность на объем выборки n , получим теоретическую частоту f e (рис. 2).

Рис. 2. Фактические и теоретические частоты прибытий в минуту
Как следует из рис. 2, теоретическая частота девяти и более прибытий не превосходит 1,0. Для того чтобы каждая категория содержала частоту, равную 1,0 или большему числу, категорию «9 и более» следует объединить с категорией «8». То есть, остается девять категорий (0, 1, 2, 3, 4, 5, 6, 7, 8 и более). Поскольку математическое ожидание распределения Пуассона определяется на основе выборочных данных, количество степеней свободы равно k – р – 1 = 9 – 1 – 1 = 7. Используя уровень значимости, равный 0,05 находим критическое значение χ 2 -статистики, имеющей 7 степеней свободы по формуле =ХИ2.ОБР(1-0,05;7) = 14,067. Решающее правило формулируется следующим образом: гипотеза Н 0 отклоняется, если χ 2 > 14,067, в противном случае гипотеза Н 0 не отклоняется.
Для расчета χ 2 воспользуемся формулой (1) (рис. 3).

Рис. 3. Расчет χ 2 -критерия согласия для распределения Пуассона
Так как χ 2 = 2,277 < 14,067, следует, что гипотезу Н 0 отклонять нельзя. Иначе говоря, у нас нет оснований утверждать, что прибытие клиентов в банк не подчиняется распределению Пуассона.
Применение χ 2 -критерия согласия для нормального распределения
В предыдущих заметках при проверке гипотез о числовых переменных использовалось предположение о том, что исследуемая генеральная совокупность имеет нормальное распределение. Для проверки этого предположения можно применять графические средства, например, блочную диаграмму или график нормального распределения (подробнее см. ). При больших объемах выборок для проверки этих предположений можно использовать χ 2 -критерий согласия для нормального распределения.
Рассмотрим в качестве примера данные о 5-летней доходности 158 инвестиционных фондов (рис. 4). Предположим, требуется поверить, имеют ли эти данные нормальное распределение. Нулевая и альтернативная гипотезы формулируются следующим образом: Н 0 : 5-летняя доходность подчиняется нормальному распределению, Н 1 : 5-летняя доходность не подчиняется нормальному распределению. Нормальное распределение имеет два параметра - математическое ожидание μ и стандартное отклонение σ, которые можно оценить на основе выборочных данных. В данном случае = 10,149 и S = 4,773.

Рис. 4. Упорядоченный массив, содержащий данные о пятилетней среднегодовой доходности 158 фондов
Данные о доходности фондов можно сгруппировать, разбив, например на классы (интервалы) шириной 5% (рис. 5).

Рис. 5. Распределение частот для пятилетней среднегодовой доходности 158 фондов
Поскольку нормальное распределение является непрерывным, необходимо определить площадь фигур, ограниченных кривой нормального распределения и границами каждого интервала. Кроме того, поскольку нормальное распределение теоретически изменяется от –∞ до +∞, необходимо учитывать площадь фигур, выходящих за пределы классов. Итак, площадь, лежащая под нормальной кривой слева от точки –10, равна площади фигуры, лежащей под стандартизованной нормальной кривой слева от величины Z, равной
Z = (–10 – 10,149) / 4,773 = –4,22
Площадь фигуры, лежащей под стандартизованной нормальной кривой слева от величины Z = –4,22 определяется по формуле =НОРМ.РАСП(-10;10,149;4,773;ИСТИНА) и приближенно равна 0,00001. Для того чтобы вычислить площадь фигуры, лежащей под нормальной кривой между точками –10 и –5, сначала необходимо вычислить площадь фигуры, лежащей слева от точки –5: =НОРМ.РАСП(-5;10,149;4,773;ИСТИНА) = 0,00075. Итак, площадь фигуры, лежащей под нормальной кривой между точками –10 и –5, равна 0,00075 – 0,00001 = 0,00074. Аналогично можно вычислить площадь фигуры, ограниченной границами каждого класса (рис. 6).

Рис. 6. Площади и ожидаемые частоты для каждого класса 5-летней доходности
Видно, что теоретические частоты в четырех крайних классах (два минимальных и два максимальных) меньше 1, поэтому проведем объединение классов, как показано на рис 7.

Рис. 7. Вычисления, связанные с применением χ 2 -критерия согласия для нормального распределения
Используем χ 2 -критерий согласия данных с нормальным распределением с помощью формулы (1). В нашем примере после объединения остаются шесть классов. Поскольку математическое ожидание и стандартное отклонение оцениваются на основе выборочных данных, количество степеней свободы равно k – p – 1 = 6 – 2 – 1 = 3. Используя уровень значимости, равный 0,05, находим, что критическое значение χ 2 -статистики, имеющее три степени свободы =ХИ2.ОБР(1-0,05;F3) = 7,815. Вычисления, связанные с применением χ 2 -критерия согласия, приведены на рис. 7.
Видно, что χ 2 -статистика = 3,964 < χ U 2 7,815, следовательно гипотезу Н 0 отклонять нельзя. Иначе говоря, у нас нет оснований утверждать, что 5-летняя доходность инвестиционных фондов, ориентированных на быстрый рост, не подчиняется нормальному распределению.
В нескольких последних заметках рассмотрены разные подходы к анализу категорийных данных. Описаны методы проверки гипотез о категорийных данных, полученных на основе анализа двух или нескольких независимых выборок. Кроме критериев «хи-квадрат», рассмотрены непараметрические процедуры. Описан ранговый критерий Уилкоксона, который используется в ситуациях, когда не выполняются условия применения t -критерия для поверки гипотезы о равенстве математических ожиданий двух независимых групп, а также критерий Крускала-Уоллиса, который является альтернативой однофакторному дисперсионному анализу (рис. 8).

Рис. 8. Структурная схема методов проверки гипотез о категорийных данных
Используются материалы книги Левин и др. Статистика для менеджеров. – М.: Вильямс, 2004. – с. 763–769
Рассмотрим Распределение ХИ-квадрат. С помощью функции MS EXCEL ХИ2.РАСП() построим графики функции распределения и плотности вероятности, поясним применение этого распределения для целей математической статистики.
Распределение ХИ-квадрат (Х 2 , ХИ2, англ. Chi - squared distribution ) применяется в различных методах математической статистики:
- при построении ;
- при ;
- при (согласуются ли эмпирические данные с нашим предположением о теоретической функции распределения или нет, англ. Goodness-of-fit)
- при (используется для определения связи между двумя категориальными переменными, англ. Chi-square test of association).
Определение : Если x 1 , x 2 , …, x n независимые случайные величины, распределенные по N(0;1), то распределение случайной величины Y=x 1 2 + x 2 2 +…+ x n 2 имеет распределение Х 2 с n степенями свободы.
Распределение Х 2 зависит от одного параметра, который называется степенью свободы (df , degrees of freedom ). Например, при построении число степеней свободы равно df=n-1, где n – размер выборки .
Плотность распределения
Х 2
выражается формулой:
Графики функций
Распределение Х 2 имеет несимметричную форму, равно n, равна 2n.
В файле примера на листе График приведены графики плотности распределения вероятности и интегральной функции распределения .

Полезное свойство ХИ2-распределения
Пусть x 1 , x 2 , …, x n независимые случайные величины, распределенные по нормальному закону
с одинаковыми параметрами μ и σ, а X cр
является арифметическим средним
этих величин x.
Тогда случайная величина y
равная
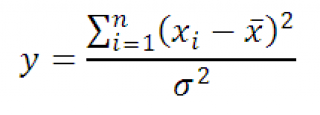
Имеет Х 2 -распределение с n-1 степенью свободы. Используя определение вышеуказанное выражение можно переписать следующим образом:

Следовательно, выборочное распределение статистики y, при выборке из нормального распределения , имеет Х 2 -распределение с n-1 степенью свободы.
Это свойство нам потребуется при . Т.к. дисперсия может быть только положительным числом, а Х 2 -распределение используется для его оценки, то y д.б. >0, как и указано в определении.
ХИ2-распределение в MS EXCEL
В MS EXCEL, начиная с версии 2010, для Х 2 -распределения имеется специальная функция ХИ2.РАСП() , английское название – CHISQ.DIST(), которая позволяет вычислить плотность вероятности (см. формулу выше) и (вероятность, что случайная величина Х, имеющая ХИ2 -распределение , примет значение меньше или равное х, P{X <= x}).
Примечание : Т.к. ХИ2-распределение является частным случаем , то формула =ГАММА.РАСП(x;n/2;2;ИСТИНА) для целого положительного n возвращает тот же результат, что и формула =ХИ2.РАСП(x;n; ИСТИНА) или =1-ХИ2.РАСП.ПХ(x;n) . А формула =ГАММА.РАСП(x;n/2;2;ЛОЖЬ) возвращает тот же результат, что и формула =ХИ2.РАСП(x;n; ЛОЖЬ) , т.е. плотность вероятности ХИ2-распределения.
Функция ХИ2.РАСП.ПХ()
возвращает функцию распределения
, точнее - правостороннюю вероятность, т.е. P{X > x}. Очевидно, что справедливо равенство
=ХИ2.РАСП.ПХ(x;n)+ ХИ2.РАСП(x;n;ИСТИНА)=1
т.к. первое слагаемое вычисляет вероятность P{X > x}, а второе P{X <= x}.
До MS EXCEL 2010 в EXCEL была только функция ХИ2РАСП() , которая позволяет вычислить правостороннюю вероятность, т.е. P{X > x}. Возможности новых функций MS EXCEL 2010 ХИ2.РАСП() и ХИ2.РАСП.ПХ() перекрывают возможности этой функции. Функция ХИ2РАСП() оставлена в MS EXCEL 2010 для совместимости.
ХИ2.РАСП() является единственной функцией, которая возвращает плотность вероятности ХИ2-распределения (третий аргумент должен быть равным ЛОЖЬ). Остальные функции возвращают интегральную функцию распределения , т.е. вероятность того, что случайная величина примет значение из указанного диапазона: P{X <= x}.
Вышеуказанные функции MS EXCEL приведены в .
Примеры
Найдем вероятность, что случайная величина Х примет значение меньше или равное заданного x : P{X <= x}. Это можно сделать несколькими функциями:
ХИ2.РАСП(x; n; ИСТИНА)
=1-ХИ2.РАСП.ПХ(x; n)
=1-ХИ2РАСП(x; n)
Функция ХИ2.РАСП.ПХ() возвращает вероятность P{X > x}, так называемую правостороннюю вероятность, поэтому, чтобы найти P{X <= x}, необходимо вычесть ее результат от 1.
Найдем вероятность, что случайная величина Х примет значение больше заданного x : P{X > x}. Это можно сделать несколькими функциями:
1-ХИ2.РАСП(x; n; ИСТИНА)
=ХИ2.РАСП.ПХ(x; n)
=ХИ2РАСП(x; n)
Обратная функция ХИ2-распределения
Обратная функция используется для вычисления альфа - , т.е. для вычисления значений x при заданной вероятности альфа , причем х должен удовлетворять выражению P{X <= x}=альфа .
Функция ХИ2.ОБР() используется для вычисления доверительных интервалов дисперсии нормального распределения .
Функция ХИ2.ОБР.ПХ() используется для вычисления , т.е. если в качестве аргумента функции указан уровень значимости, например 0,05, то функция вернет такое значение случайной величины х, для которого P{X>x}=0,05. В качестве сравнения: функция ХИ2.ОБР() вернет такое значение случайной величины х, для которого P{X<=x}=0,05.
В MS EXCEL 2007 и ранее вместо ХИ2.ОБР.ПХ() использовалась функция ХИ2ОБР() .
Вышеуказанные функции можно взаимозаменять, т.к. следующие формулы возвращают один и тот же результат:
=ХИ.ОБР(альфа;n)
=ХИ2.ОБР.ПХ(1-альфа;n)
=ХИ2ОБР(1- альфа;n)
Некоторые примеры расчетов приведены в файле примера на листе Функции .
Функции MS EXCEL, использующие ХИ2-распределение
Ниже приведено соответствие русских и английских названий функций:
ХИ2.РАСП.ПХ()
- англ. название CHISQ.DIST.RT, т.е. CHI-SQuared DISTribution Right Tail, the right-tailed Chi-square(d) distribution
ХИ2.ОБР()
- англ. название CHISQ.INV, т.е. CHI-SQuared distribution INVerse
ХИ2.ПХ.ОБР()
- англ. название CHISQ.INV.RT, т.е. CHI-SQuared distribution INVerse Right Tail
ХИ2РАСП()
- англ. название CHIDIST, функция эквивалентна CHISQ.DIST.RT
ХИ2ОБР()
- англ. название CHIINV, т.е. CHI-SQuared distribution INVerse
Оценка параметров распределения
Т.к. обычно ХИ2-распределение используется для целей математической статистики (вычисление доверительных интервалов, проверки гипотез и др.), и практически никогда для построения моделей реальных величин, то для этого распределения обсуждение оценки параметров распределения здесь не производится.
Приближение ХИ2-распределения нормальным распределением
При числе степеней свободы n>30 распределение Х 2
хорошо аппроксимируется нормальным распределением
со средним значением
μ=n и дисперсией σ
=2*n (см. файл примера лист Приближение
).
Министерство образования и науки Российской Федерации
Федеральное агентство по образованию города Иркутска
Байкальский государственный университет экономики и права
Кафедра Информатики и Кибернетики
Распределение "хи-квадрат" и его применение
Колмыкова Анна Андреевна
студентка 2 курса
группы ИС-09-1
Иркутск 2010
Введение
1. Распределение "хи-квадрат"
Приложение
Заключение
Список используемой литературы
Введение
Как подходы, идеи и результаты теории вероятностей используются в нашей жизни?
Базой является вероятностная модель реального явления или процесса, т.е. математическая модель, в которой объективные соотношения выражены в терминах теории вероятностей. Вероятности используются, прежде всего, для описания неопределенностей, которые необходимо учитывать при принятии решений. Имеются в виду, как нежелательные возможности (риски), так и привлекательные ("счастливый случай"). Иногда случайность вносится в ситуацию сознательно, например, при жеребьевке, случайном отборе единиц для контроля, проведении лотерей или опросов потребителей.
Теория вероятностей позволяет по одним вероятностям рассчитать другие, интересующие исследователя.
Вероятностная модель явления или процесса является фундаментом математической статистики. Используются два параллельных ряда понятий – относящиеся к теории (вероятностной модели) и относящиеся к практике (выборке результатов наблюдений). Например, теоретической вероятности соответствует частота, найденная по выборке. Математическому ожиданию (теоретический ряд) соответствует выборочное среднее арифметическое (практический ряд). Как правило, выборочные характеристики являются оценками теоретических. При этом величины, относящиеся к теоретическому ряду, "находятся в головах исследователей", относятся к миру идей (по древнегреческому философу Платону), недоступны для непосредственного измерения. Исследователи располагают лишь выборочными данными, с помощью которых они стараются установить интересующие их свойства теоретической вероятностной модели.
Зачем же нужна вероятностная модель? Дело в том, что только с ее помощью можно перенести свойства, установленные по результатам анализа конкретной выборки, на другие выборки, а также на всю так называемую генеральную совокупность. Термин "генеральная совокупность" используется, когда речь идет о большой, но конечной совокупности изучаемых единиц. Например, о совокупности всех жителей России или совокупности всех потребителей растворимого кофе в Москве. Цель маркетинговых или социологических опросов состоит в том, чтобы утверждения, полученные по выборке из сотен или тысяч человек, перенести на генеральные совокупности в несколько миллионов человек. При контроле качества в роли генеральной совокупности выступает партия продукции.
Чтобы перенести выводы с выборки на более обширную совокупность, необходимы те или иные предположения о связи выборочных характеристик с характеристиками этой более обширной совокупности. Эти предположения основаны на соответствующей вероятностной модели.
Конечно, можно обрабатывать выборочные данные, не используя ту или иную вероятностную модель. Например, можно рассчитывать выборочное среднее арифметическое, подсчитывать частоту выполнения тех или иных условий и т.п. Однако результаты расчетов будут относиться только к конкретной выборке, перенос полученных с их помощью выводов на какую-либо иную совокупность некорректен. Иногда подобную деятельность называют "анализ данных". По сравнению с вероятностно-статистическими методами анализ данных имеет ограниченную познавательную ценность.
Итак, использование вероятностных моделей на основе оценивания и проверки гипотез с помощью выборочных характеристик – вот суть вероятностно-статистических методов принятия решений.
Распределение "хи-квадрат"
С помощью нормального распределения определяются три распределения, которые в настоящее время часто используются при статистической обработке данных. Это распределения Пирсона ("хи – квадрат"), Стьюдента и Фишера.
Мы остановимся на распределении
("хи – квадрат"). Впервые это распределение было исследовано астрономом Ф.Хельмертом в 1876 году. В связи с гауссовской теорией ошибок он исследовал суммы квадратов n независимых стандартно нормально распределенных случайных величин. Позднее Карл Пирсон (Karl Pearson) дал имя данной функции распределения "хи – квадрат". И сейчас распределение носит его имя.Благодаря тесной связи с нормальным распределением, χ2-распределение играет важную роль в теории вероятностей и математической статистике. χ2-распределение, и многие другие распределения, которые определяются посредством χ2-распределения (например - распределение Стьюдента), описывают выборочные распределения различных функций от нормально распределенных результатов наблюдений и используются для построения доверительных интервалов и статистических критериев.
Распределение Пирсона
(хи - квадрат) – распределение случайной величиныгде X1, X2,…, Xn - нормальные независимые случайные величины, причем математическое ожидание каждой из них равно нулю, а среднее квадратическое отклонение - единице.Сумма квадратов
распределена по закону
("хи – квадрат").При этом число слагаемых, т.е. n, называется "числом степеней свободы" распределения хи – квадрат. C увеличением числа степеней свободы распределение медленно приближается к нормальному.
Плотность этого распределения

Итак, распределение χ2 зависит от одного параметра n – числа степеней свободы.
Функция распределения χ2 имеет вид:

если χ2≥0. (2.7.)
На Рисунок 1 изображен график плотности вероятности и функции χ2 – распределения для разных степеней свободы.

Рисунок 1 Зависимость плотности вероятности φ (x) в распределении χ2 (хи – квадрат) при разном числе степеней свободы.
Моменты распределения "хи-квадрат":
Распределение "хи-квадрат" используют при оценивании дисперсии (с помощью доверительного интервала), при проверке гипотез согласия, однородности, независимости, прежде всего для качественных (категоризованных) переменных, принимающих конечное число значений, и во многих других задачах статистического анализа данных.
2. "Хи-квадрат" в задачах статистического анализа данных
Статистические методы анализа данных применяются практически во всех областях деятельности человека. Их используют всегда, когда необходимо получить и обосновать какие-либо суждения о группе (объектов или субъектов) с некоторой внутренней неоднородностью.
Современный этап развития статистических методов можно отсчитывать с 1900 г., когда англичанин К. Пирсон основал журнал "Biometrika". Первая треть ХХ в. прошла под знаком параметрической статистики. Изучались методы, основанные на анализе данных из параметрических семейств распределений, описываемых кривыми семейства Пирсона. Наиболее популярным было нормальное распределение. Для проверки гипотез использовались критерии Пирсона, Стьюдента, Фишера. Были предложены метод максимального правдоподобия, дисперсионный анализ, сформулированы основные идеи планирования эксперимента.
Распределение "хи-квадрат" является одним из наиболее широко используемых в статистике для проверки статистических гипотез. На основе распределения "хи-квадрат" построен один из наиболее мощных критериев согласия – критерий "хи-квадрата" Пирсона.
Критерием согласия называют критерий проверки гипотезы о предполагаемом законе неизвестного распределения.
Критерий χ2 ("хи-квадрат") используется для проверки гипотезы различных распределений. В этом заключается его достоинство.
Расчетная формула критерия равна

где m и m’ - соответственно эмпирические и теоретические частоты
рассматриваемого распределения;
n - число степеней свободы.
Для проверки нам необходимо сравнивать эмпирические (наблюдаемые) и теоретические (вычисленные в предположении нормального распределения) частоты.
При полном совпадении эмпирических частот с частотами, вычисленными или ожидаемыми S (Э – Т) = 0 и критерий χ2 тоже будет равен нулю. Если же S (Э – Т) не равно нулю это укажет на несоответствие вычисленных частот эмпирическим частотам ряда. В таких случаях необходимо оценить значимость критерия χ2, который теоретически может изменяться от нуля до бесконечности. Это производится путем сравнения фактически полученной величины χ2ф с его критическим значением (χ2st).Нулевая гипотеза, т. е. предположение, что расхождение между эмпирическими и теоретическими или ожидаемыми частотами носит случайный характер, опровергается, если χ2ф больше или равно χ2st для принятого уровня значимости (a) и числа степеней свободы (n).


