Binomska porazdelitev je njena mejna oblika. Binomska porazdelitev
Seveda je pri izračunu kumulativne porazdelitvene funkcije treba uporabiti omenjeno povezavo med binomsko in beta porazdelitvijo. Ta metoda je očitno boljša od neposrednega seštevanja, če je n > 10.
V klasičnih učbenikih o statistiki se za pridobitev vrednosti binomske porazdelitve pogosto priporoča uporaba formul, ki temeljijo na mejnih izrekih (kot je formula Moivre-Laplace). Opozoriti je treba, da s čisto računalniškega vidika vrednost teh izrekov je blizu ničle, še posebej zdaj, ko ima skoraj vsaka miza močan računalnik. Glavna pomanjkljivost zgornjih približkov je njihova popolnoma nezadostna natančnost za vrednosti n, značilne za večino aplikacij. Nič manjša pomanjkljivost je pomanjkanje kakršnih koli jasnih priporočil o uporabnosti tega ali onega približka (standardna besedila zagotavljajo le asimptotične formulacije; ne spremljajo jih ocene točnosti in so zato malo uporabna). Rekel bi, da sta obe formuli primerni le za n< 200 и для совсем грубых, ориентировочных расчетов, причем делаемых “вручную” с помощью статистических таблиц. А вот связь между биномиальным распределением и бета-распределением позволяет вычислять биномиальное распределение достаточно экономно.
Tu ne razmišljam o problemu iskanja kvantilov: za diskretne porazdelitve je trivialen, v tistih problemih, kjer se pojavijo takšne porazdelitve, pa praviloma ni pomemben. Če so kvantili še vedno potrebni, priporočam, da problem preoblikujete tako, da delate z vrednostmi p (opazovane pomembnosti). Tu je primer: pri izvajanju nekaterih izčrpnih iskalnih algoritmov je treba na vsakem koraku preizkusiti statistično hipotezo o binomski naključni spremenljivki. Glede na klasičen pristop Na vsakem koraku morate izračunati kriterijsko statistiko in njeno vrednost primerjati z mejo kritične množice. Ker pa je algoritem izčrpen, je treba vsakič na novo določiti mejo kritične množice (navsezadnje se velikost vzorca spreminja iz koraka v korak), kar neproduktivno povečuje časovne stroške. Sodoben pristop priporoča izračun opazovane pomembnosti in primerjavo z verjetnost zaupanja, prihranek pri iskanju kvantilov.
Zato v spodnjih kodah ni izračuna inverzne funkcije, temveč je podana funkcija rev_binomialDF, ki izračuna verjetnost p uspeha v posameznem poskusu glede na podano število poskusov n, število uspehov v njih in vrednost y verjetnosti doseganja teh m uspehov. To uporablja prej omenjeno povezavo med binomsko in beta porazdelitvijo.
Pravzaprav vam ta funkcija omogoča, da pridobite meje intervalov zaupanja. Recimo, da imamo v n binomskih poskusih m uspehov. Kot je znano, je leva meja dvostranska interval zaupanja za parameter p s stopnjo zaupanja je enak 0, če je m = 0, in za je rešitev enačbe  . Podobno je desna meja 1, če je m = n, in za je rešitev enačbe
. Podobno je desna meja 1, če je m = n, in za je rešitev enačbe  . Iz tega sledi, da moramo za iskanje leve meje rešiti relativno enačbo
. Iz tega sledi, da moramo za iskanje leve meje rešiti relativno enačbo  , in najti pravo – enačbo
, in najti pravo – enačbo  . Rešijo se v funkcijah binom_leftCI in binom_rightCI, ki vrneta zgornjo oziroma spodnjo mejo dvostranskega intervala zaupanja.
. Rešijo se v funkcijah binom_leftCI in binom_rightCI, ki vrneta zgornjo oziroma spodnjo mejo dvostranskega intervala zaupanja.
Rad bi opozoril, da če ne potrebujete popolnoma neverjetne natančnosti, lahko za dovolj velik n uporabite naslednji približek [B.L. van der Waerden, Matematična statistika. M: IL, 1960, pogl. 2, razdelek 7]:  , kjer je g – kvantil normalna porazdelitev. Vrednost tega približka je v tem, da obstajajo zelo preprosti približki, ki vam omogočajo izračun kvantilov normalne porazdelitve (glejte besedilo o izračunu normalne porazdelitve in ustrezen del tega priročnika). V moji praksi (predvsem pri n > 100) je ta aproksimacija dala približno 3-4 števke, kar je praviloma povsem dovolj.
, kjer je g – kvantil normalna porazdelitev. Vrednost tega približka je v tem, da obstajajo zelo preprosti približki, ki vam omogočajo izračun kvantilov normalne porazdelitve (glejte besedilo o izračunu normalne porazdelitve in ustrezen del tega priročnika). V moji praksi (predvsem pri n > 100) je ta aproksimacija dala približno 3-4 števke, kar je praviloma povsem dovolj.
Za izračun z uporabo naslednjih kod boste potrebovali datoteki betaDF.h, betaDF.cpp (glejte razdelek o distribuciji beta), kot tudi logGamma.h, logGamma.cpp (glejte Dodatek A). Ogledate si lahko tudi primer uporabe funkcij.
Datoteka binomialDF.h
| #ifndef __BINOMIAL_H__ #include "betaDF.h" dvojni binomDF(dvojni poskusi, dvojni uspehi, dvojni p); /* * Naj obstajajo "poskusi" neodvisnih opazovanj * z verjetnostjo "p" uspeha pri vsakem. |
* Izračunajte verjetnost B(uspehi|poskusi,p), da je število * uspehov med 0 in "uspehi" (vključno).
|
/***********************************************************/
/* */ dvojni rev_binomialDF(dvojni poskusi, dvojni uspehi, dvojni y); /* * Naj bo verjetnost y vsaj m uspehov * v poskusih, ki testirajo Bernoullijevo shemo. Funkcija poišče verjetnost p* uspeha v posameznem poskusu.* * Pri izračunih je uporabljena naslednja relacija * * 1 - p = rev_Beta(poskusi-uspehi| uspehi+1, y). |
Oglejmo si binomsko porazdelitev, izračunajmo njeno matematično pričakovanje, varianco in način. S pomočjo funkcije MS EXCEL BINOM.DIST() bomo zgradili grafe porazdelitvene funkcije in gostote verjetnosti. Ocenimo porazdelitveni parameter p, matematično pričakovanje porazdelitev in standardni odklon. Upoštevajmo tudi Bernoullijevo porazdelitev.
Opredelitev. Naj se odvijajo n testov, pri katerih se lahko zgodita samo 2 dogodka: dogodek »uspeh« z verjetnostjo str ali dogodek »napake« z verjetnostjo q =1-p (tako imenovani Bernoullijeva shema,Bernoulliposkusi).
Verjetnost prejema točno x uspeh pri teh n testi je enako:
Število uspehov v vzorcu x je naključna spremenljivka, ki ima Binomska porazdelitev(angleščina) Binomdistribucija) str in n– so parametri te porazdelitve.
Zapomnite si, da morate uporabiti Bernoullijeve sheme in temu primerno Binomska porazdelitev, izpolnjeni morajo biti naslednji pogoji:
- Vsak test mora imeti natanko dva izida, ki se običajno imenujeta "uspeh" in "neuspeh".
- rezultat posameznega testa ne sme biti odvisen od rezultatov prejšnjih testov (test neodvisnosti).
- verjetnost uspeha str mora biti konstantna za vse teste.
Binomska porazdelitev v MS EXCEL
V MS EXCEL, od različice 2010, za Binomska porazdelitev obstaja funkcija BINOM.DIST(), angleško ime- BINOM.DIST(), ki omogoča izračun verjetnosti, da bo vzorec natančno vseboval X"uspeh" (tj. funkcija gostote verjetnosti p(x), glej formulo zgoraj) in kumulativna porazdelitvena funkcija(verjetnost, da bo vzorec imel x ali manj "uspehov", vključno z 0).
Pred MS EXCEL 2010 je imel EXCEL funkcijo BINOMDIST(), ki omogoča tudi izračun distribucijska funkcija in gostota verjetnosti p(x). BINOMIST() je opuščen v MS EXCEL 2010 zaradi združljivosti.
Primer datoteke vsebuje grafe porazdelitev gostote verjetnosti in .

Binomska porazdelitev ima oznako B(n; str) .
Opomba: Za gradnjo integralna funkcija distribucija diagram popolnega tipa Urnik, Za gostota porazdelitve – Histogram z združevanjem. Za več informacij o ustvarjanju grafikonov preberite članek Osnovne vrste grafikonov.
Opomba: Za lažje pisanje formul so bila v vzorčni datoteki ustvarjena imena za parametre Binomska porazdelitev: n in str.

Primer datoteke prikazuje različne izračune verjetnosti z uporabo funkcij MS EXCEL:
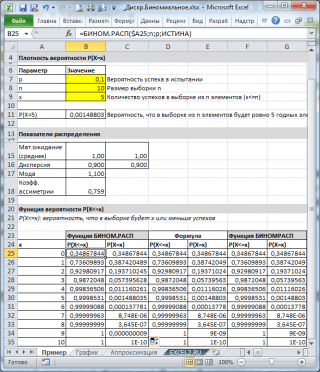
Kot lahko vidite na zgornji sliki, se predpostavlja, da:
- Neskončna populacija, iz katere je vzet vzorec, vsebuje 10 % (ali 0,1) veljavnih elementov (parameter str, tretji argument funkcije = BINOM.DIST() )
- Za izračun verjetnosti, da bo v vzorcu 10 elementov (parameter n, drugi argument funkcije) bo natanko 5 veljavnih elementov (prvi argument), napisati morate formulo: =BINOM.DIST(5, 10, 0,1, FALSE)
- Zadnji, četrti element je nastavljen = FALSE, tj. vrednost funkcije je vrnjena gostota porazdelitve.
Če je vrednost četrtega argumenta = TRUE, potem funkcija BINOM.DIST() vrne vrednost kumulativna porazdelitvena funkcija ali samo Distribucijska funkcija. V tem primeru lahko izračunate verjetnost, da bo število dobrih elementov v vzorcu iz določenega obsega, na primer 2 ali manj (vključno z 0).
Če želite to narediti, morate napisati formulo:
= BINOM.DIST(2; 10; 0,1; TRUE)
Opomba: Za vrednost x, ki ni celo število, . Naslednje formule bodo na primer vrnile isto vrednost:
=BINOM.DIST( 2
; 10; 0,1; TRUE)
=BINOM.DIST( 2,9
; 10; 0,1; TRUE)
Opomba: V vzorčni datoteki gostota verjetnosti in distribucijska funkcija izračunano tudi z uporabo definicije in funkcije NUMBERCOMB().
Indikatorji distribucije
IN primer datoteke na delovnem listu Primer Obstajajo formule za izračun nekaterih kazalnikov distribucije:
- =n*p;
- (standardni odklon na kvadrat) = n*p*(1-p);
- = (n+1)*p;
- =(1-2*p)*ROOT(n*p*(1-p)).
Izpeljimo formulo matematično pričakovanje Binomska porazdelitev uporabo Bernoullijevo vezje.
Po definiciji je naključna spremenljivka X v Bernoullijeva shema(Bernoullijeva naključna spremenljivka) ima distribucijska funkcija:

Ta distribucija se imenuje Bernoullijeva porazdelitev.
Opomba: Bernoullijeva porazdelitev – poseben primer Binomska porazdelitev s parametrom n=1.
Ustvarimo 3 nize po 100 števil z različnimi verjetnostmi uspeha: 0,1; 0,5 in 0,9. Če želite to narediti v oknu Generacija naključna števila Za vsako verjetnost p nastavimo naslednje parametre:

Opomba: Če nastavite možnost Naključno razprševanje (Naključno seme), potem lahko izberete določen naključni niz ustvarjenih števil. Na primer, če nastavite to možnost =25, lahko ustvarite iste nize naključnih števil na različnih računalnikih (če so seveda drugi parametri porazdelitve enaki). Vrednost možnosti ima lahko celo število od 1 do 32.767 Ime možnosti Naključno razprševanje lahko zmede. Bolje bi bilo prevesti kot Pokličite številko z naključnimi številkami.
Posledično bomo imeli 3 stolpce po 100 številk, na podlagi katerih lahko ocenimo npr. verjetnost uspeha str po formuli: Število uspehov/100(cm. primer datoteke GenerationBernoulli).

Opomba: Za Bernoullijeve porazdelitve s p=0,5 lahko uporabite formulo =RANDBETWEEN(0;1), ki ustreza .
Generiranje naključnih števil. Binomska porazdelitev
Predpostavimo, da je v vzorcu 7 izdelkov z napako. To pomeni, da je »zelo verjetno«, da se je delež izdelkov z napako spremenil str, kar je značilnost našega proizvodni proces. Čeprav je taka situacija »zelo verjetna«, obstaja možnost (tveganje alfa, napaka tipa 1, »lažni alarm«), da str ostala nespremenjena, povečano število izdelkov z napako pa je posledica naključnega vzorčenja.
Kot je razvidno iz spodnje slike, je 7 število izdelkov z napako, ki je sprejemljivo za postopek s p=0,21 pri enaki vrednosti Alfa. To ponazarja, da ko je mejna vrednost pomanjkljivih predmetov v vzorcu presežena, str»najverjetneje« se je povečalo. Besedna zveza "najverjetneje" pomeni, da obstaja le 10-odstotna verjetnost (100%-90%), da je odstopanje odstotka okvarjenih izdelkov nad mejno vrednostjo samo zaradi naključnih razlogov.

Tako lahko prekoračitev mejnega števila izdelkov z napako v vzorcu služi kot signal, da je proces moten in je začel proizvajati rabljene izdelke. O višji odstotek izdelkov z napako.
Opomba: Pred MS EXCEL 2010 je imel EXCEL funkcijo CRITBINOM(), ki je enakovredna BINOM.INV(). CRITBINOM() je opuščen v MS EXCEL 2010 in novejšem zaradi združljivosti.
Povezava binomske porazdelitve z drugimi porazdelitvami
Če je parameter n Binomska porazdelitev teži v neskončnost in str teži k 0, potem v tem primeru Binomska porazdelitev se lahko približa.
Lahko oblikujemo pogoje, ko je aproksimacija Poissonova porazdelitev deluje dobro:
- str<0,1 (manj str in več n, bolj natančen je približek);
- str>0,9 (glede na to q=1- str, izračune v tem primeru je treba opraviti skozi q(A X je treba zamenjati z n- x). Zato manj q in več n, bolj natančen je približek).
Pri 0,1<=p<=0,9 и n*p>10 Binomska porazdelitev se lahko približa.
v zameno, Binomska porazdelitev lahko služi kot dober približek, ko je velikost populacije N Hipergeometrična porazdelitev veliko večji od velikosti vzorca n (tj. N>>n ali n/N<<1).
Več podrobnosti o razmerju med zgornjimi porazdelitvami najdete v članku. Navedeni so tudi primeri aproksimacije in pojasnjeni so pogoji, kdaj je to mogoče in s kakšno natančnostjo.
NASVET: O drugih distribucijah MS EXCEL si lahko preberete v članku.
pozdravljena Že vemo, kaj je porazdelitev verjetnosti. Lahko je diskretna ali zvezna in izvedeli smo, da se imenuje funkcija gostote verjetnosti. . Lahko bi bilo tudi "glave", "repi", "glave", "repi", "repi". In to pravim, ker je pomembno razumeti, kje uporabiti umestitve in kje kombinacije. je enako 10. Vsaka situacija ima verjetnost 1/32, tako da je to spet enako 5/16.
Zdaj pa preučimo nekaj pogostejših distribucij. Recimo, da imam kovanec, pošten kovanec, in ga bom vrgel 5-krat. Definiral bom tudi naključno spremenljivko X, označeno z veliko začetnico X, ki bo enaka številu glav v 5 metih. Mogoče imam 5 kovancev, vrgel jih bom vse naenkrat in preštel, koliko glav dobim. Lahko pa bi imel en kovanec, bi ga lahko vrgel 5-krat in preštel, kolikokrat sem dobil glave. Pravzaprav ni pomembno. n Toda predpostavimo, da imam en kovanec in ga bom vrgel 5-krat. Potem ne bomo imeli negotovosti. Lahko pa bi imel en kovanec, bi ga lahko vrgel 5-krat in preštel, kolikokrat sem dobil glave. Torej, tukaj je moja definicija
naključna spremenljivka:
- Binomska porazdelitev je ena najpomembnejših verjetnostnih porazdelitev diskretno spremenljive naključne spremenljivke. n Binomska porazdelitev je verjetnostna porazdelitev števila Lahko pa bi imel en kovanec, bi ga lahko vrgel 5-krat in preštel, kolikokrat sem dobil glave. m
- pojav dogodka Lahko pa bi imel en kovanec, bi ga lahko vrgel 5-krat in preštel, kolikokrat sem dobil glave. A str;
- V
medsebojno neodvisna opazovanja n. Pogosto dogodek Lahko pa bi imel en kovanec, bi ga lahko vrgel 5-krat in preštel, kolikokrat sem dobil glave. se imenuje "uspeh" opazovanja, nasprotni dogodek pa se imenuje "neuspeh", vendar je ta oznaka zelo pogojna. Definiral bom tudi naključno spremenljivko X, označeno z veliko začetnico X, ki bo enaka številu glav v 5 metih. Pogoji binomske porazdelitve
![]()
![]() ,
,
skupaj izvedenih str sojenja, v katerih dogodek Lahko pa bi imel en kovanec, bi ga lahko vrgel 5-krat in preštel, kolikokrat sem dobil glave.;
q = 1 - str se lahko pojavi ali ne;
dogodek v vsakem poskusu se lahko pojavi z enako verjetnostjo testi so med seboj neodvisni. n Verjetnost, da v Definiral bom tudi naključno spremenljivko X, označeno z veliko začetnico X, ki bo enaka številu glav v 5 metih. dogodek testiranja n - Definiral bom tudi naključno spremenljivko X, označeno z veliko začetnico X, ki bo enaka številu glav v 5 metih. točno bo prišlo B1 krat, se lahko izračuna z uporabo Bernoullijeve formule:
![]() ,
,
kje q = 1 - str- verjetnost nastanka dogodka
![]() .
.
- verjetnost pojava nasprotnega dogodka. Definiral bom tudi naključno spremenljivko X, označeno z veliko začetnico X, ki bo enaka številu glav v 5 metih. Ugotovimo n - Definiral bom tudi naključno spremenljivko X, označeno z veliko začetnico X, ki bo enaka številu glav v 5 metih. zakaj je binomska porazdelitev povezana z Bernoullijevo formulo na zgoraj opisan način? n. Dogodek - število uspehov pri Definiral bom tudi naključno spremenljivko X, označeno z veliko začetnico X, ki bo enaka številu glav v 5 metih. testi so razdeljeni na več možnosti, pri vsaki od katerih je dosežen uspeh
testi in neuspeh - v Definiral bom tudi naključno spremenljivko X, označeno z veliko začetnico X, ki bo enaka številu glav v 5 metih. testi. Razmislimo o eni od teh možnosti - Lahko pa bi imel en kovanec, bi ga lahko vrgel 5-krat in preštel, kolikokrat sem dobil glave.. S pravilom za seštevanje verjetnosti pomnožimo verjetnosti nasprotnih dogodkov: n in če označimo
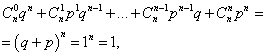
, To
V praksi je pogosto treba izračunati verjetnosti "ne več kot Definiral bom tudi naključno spremenljivko X, označeno z veliko začetnico X, ki bo enaka številu glav v 5 metih. uspeh v n testi" ali "vsaj Definiral bom tudi naključno spremenljivko X, označeno z veliko začetnico X, ki bo enaka številu glav v 5 metih. uspeh v n testi". Za to se uporabljajo naslednje formule.
Integralna funkcija, tj verjetnost F(Definiral bom tudi naključno spremenljivko X, označeno z veliko začetnico X, ki bo enaka številu glav v 5 metih.) kaj je notri n opazovalni dogodek Lahko pa bi imel en kovanec, bi ga lahko vrgel 5-krat in preštel, kolikokrat sem dobil glave. nič več ne bo prišlo Definiral bom tudi naključno spremenljivko X, označeno z veliko začetnico X, ki bo enaka številu glav v 5 metih. enkrat, se lahko izračuna po formuli:
Po vrsti verjetnost F(≥Definiral bom tudi naključno spremenljivko X, označeno z veliko začetnico X, ki bo enaka številu glav v 5 metih.) kaj je notri n opazovalni dogodek Lahko pa bi imel en kovanec, bi ga lahko vrgel 5-krat in preštel, kolikokrat sem dobil glave. ne bo prišlo nič manj Definiral bom tudi naključno spremenljivko X, označeno z veliko začetnico X, ki bo enaka številu glav v 5 metih. enkrat, se izračuna po formuli:
Včasih je bolj priročno izračunati verjetnost, da n opazovalni dogodek Lahko pa bi imel en kovanec, bi ga lahko vrgel 5-krat in preštel, kolikokrat sem dobil glave. nič več ne bo prišlo Definiral bom tudi naključno spremenljivko X, označeno z veliko začetnico X, ki bo enaka številu glav v 5 metih. krat, skozi verjetnost nasprotnega dogodka:
![]() .
.
Katero formulo uporabiti, je odvisno od tega, kateri od njih ima vsoto manj členov.
Značilnosti binomske porazdelitve se izračunajo z uporabo naslednjih formul .
Matematično pričakovanje: .
Razpršenost: .
Standardni odklon: .
Binomska porazdelitev in izračuni v MS Excelu
Binomska verjetnost p n ( Definiral bom tudi naključno spremenljivko X, označeno z veliko začetnico X, ki bo enaka številu glav v 5 metih.) in vrednosti integralne funkcije F(Definiral bom tudi naključno spremenljivko X, označeno z veliko začetnico X, ki bo enaka številu glav v 5 metih.) lahko izračunate s funkcijo MS Excel BINOM.DIST. Spodaj je prikazano okno za ustrezen izračun (levi klik za povečavo).

MS Excel zahteva vnos naslednjih podatkov:
- število uspehov;
- število testov;
- verjetnost uspeha;
- integral - logična vrednost: 0 - če morate izračunati verjetnost p n ( Definiral bom tudi naključno spremenljivko X, označeno z veliko začetnico X, ki bo enaka številu glav v 5 metih.) in 1 - če je verjetnost F(Definiral bom tudi naključno spremenljivko X, označeno z veliko začetnico X, ki bo enaka številu glav v 5 metih.).
Primer 1. Vodja podjetja je povzel podatke o številu prodanih kamer v zadnjih 100 dneh. V tabeli so povzeti podatki in izračunane verjetnosti, da bo določeno število kamer dnevno prodano.
Dan se konča z dobičkom, če se proda 13 ali več kamer. Verjetnost, da se bo dan končal z dobičkom:
![]()
Verjetnost, da bo dan opravljen brez dobička:

Naj bo verjetnost, da se dan dela z dobičkom, konstantna in enaka 0,61, število prodanih kamer na dan pa ni odvisno od dneva. Nato lahko uporabimo binomsko porazdelitev, kjer je dogodek Lahko pa bi imel en kovanec, bi ga lahko vrgel 5-krat in preštel, kolikokrat sem dobil glave.- dan bo opravljen z dobičkom, - brez dobička.
Verjetnost, da bo vseh 6 dni izpeljanih z dobičkom:
![]() .
.
Enak rezultat dobimo s funkcijo MS Excel BINOM.DIST (vrednost integralne vrednosti je 0):
p 6 (6 ) = BINOM.DIST(6; 6; 0,61; 0) = 0,052.
Verjetnost, da bodo od 6 dni 4 ali več dni opravljeni z dobičkom:
skupaj izvedenih ![]() ,
,
![]() ,
,
S pomočjo MS Excelove funkcije BINOM.DIST izračunamo verjetnost, da od 6 dni ne bomo več kot 3 dni zaključili z dobičkom (vrednost integralne vrednosti je 1):
p 6 (≤3 ) = BINOM.DIST(3; 6; 0,61; 1) = 0,435.
Verjetnost, da bo vseh 6 dni oddelanih z izgubami:
![]() ,
,
Isti indikator lahko izračunamo s pomočjo funkcije MS Excel BINOM.DIST:
p 6 (0 ) = BINOM.DIST(0; 6; 0,61; 0) = 0,0035.
Rešite problem sami in nato poglejte rešitev
Primer 2. V žari sta 2 beli krogli in 3 črne krogle. Iz žare se vzame kroglica, barva se nastavi in vrne nazaj. Poskus se ponovi 5-krat. Število pojavitev belih kroglic je diskretna naključna spremenljivka X, porazdeljeno po binomskem zakonu. Sestavite zakon porazdelitve naključne spremenljivke. Določite način, matematično pričakovanje in disperzijo.
Nadaljujmo z reševanjem težav skupaj
Primer 3. Iz kurirske službe smo šli na mesta n= 5 kurirjev. Vsak kurir je verjetno str= 0,3, ne glede na druge, zamuja za objekt. Diskretna naključna spremenljivka X- število zamudnih kurirjev. Konstruirajte porazdelitveni niz za to naključno spremenljivko. Poiščite njegovo matematično pričakovanje, varianco, standardni odklon. Poiščite verjetnost, da bosta vsaj dva kurirja zamudila na predmete.
V tej in naslednjih nekaj objavah si bomo ogledali matematične modele naključnih dogodkov. Matematični model je matematični izraz, ki predstavlja naključno spremenljivko. Za diskretne naključne spremenljivke je ta matematični izraz znan kot porazdelitvena funkcija.
Če vam problem omogoča eksplicitno pisanje matematičnega izraza, ki predstavlja naključno spremenljivko, lahko izračunate natančno verjetnost katere koli njene vrednosti. V tem primeru lahko izračunate in navedete vse vrednosti distribucijske funkcije. Različne porazdelitve naključnih spremenljivk se srečujejo v poslovnih, socioloških in medicinskih aplikacijah. Ena najbolj uporabnih porazdelitev je binomska.
Binomska porazdelitev uporablja za simulacijo situacij, za katere so značilne naslednje značilnosti.
- Vzorec je sestavljen iz določenega števila elementov n, ki predstavlja rezultate določenega testa.
- Vsak vzorčni element pripada eni od dveh medsebojno izključujočih se kategorij, ki izčrpata celoten vzorčni prostor. Običajno se ti dve kategoriji imenujeta uspeh in neuspeh.
- Verjetnost uspeha r je konstantna. Zato je verjetnost neuspeha 1 – str.
- Izid (tj. uspeh ali neuspeh) katerega koli poskusa ni odvisen od izida drugega poskusa. Da bi zagotovili neodvisnost rezultatov, so vzorčni elementi običajno pridobljeni z uporabo dveh različnih metod. Vsak element v vzorcu je naključno izbran iz neskončne populacije brez reverzije ali iz končne populacije z reverzijo.
Prenesite opombo v ali obliki, primeri v obliki
Binomska porazdelitev se uporablja za oceno števila uspehov v vzorcu, sestavljenem iz n opazovanja. Vzemimo za primer naročanje. Za oddajo naročila lahko stranke Saxon Company uporabijo interaktivni elektronski obrazec in ga pošljejo podjetju. Informacijski sistem nato preveri napake, nepopolne ali nepravilne podatke v naročilih. Vsako zadevno naročilo je označeno in vključeno v dnevno poročilo o izjemah. Podatki, ki jih podjetje zbira, kažejo, da je verjetnost napak pri naročilih 0,1. Podjetje bi želelo vedeti, kakšna je verjetnost, da v danem vzorcu najde določeno število napačnih naročil. Recimo, da kupci izpolnijo štiri elektronske obrazce. Kakšna je verjetnost, da bodo vsa naročila brez napak? Kako izračunati to verjetnost? Pod uspehom bomo razumeli napako pri izpolnjevanju obrazca, vse ostale rezultate pa bomo obravnavali kot neuspešne. Spomnimo se, da nas zanima število napačnih naročil v danem vzorcu.
Kakšne rezultate lahko opazimo? Če je vzorec sestavljen iz štirih naročil, so lahko eden, dva, tri ali vsi štirje nepravilni, vsi pa so lahko pravilni. Ali lahko naključna spremenljivka, ki opisuje število nepravilno izpolnjenih obrazcev, zavzame kakšno drugo vrednost? To ni mogoče, ker število nepravilnih obrazcev ne sme preseči velikosti vzorca n ali biti negativen. Tako naključna spremenljivka, ki upošteva zakon binomske porazdelitve, ima vrednosti od 0 do n.
Predpostavimo, da so v vzorcu štirih naročil opaženi naslednji rezultati:
Kakšna je verjetnost, da najdemo tri napačna naročila v vzorcu štirih naročil v navedenem vrstnem redu? Ker je preliminarna raziskava pokazala, da je verjetnost napake pri izpolnjevanju obrazca 0,10, se verjetnosti zgornjih izidov izračunajo na naslednji način:
Ker izidi niso odvisni drug od drugega, je verjetnost navedenega zaporedja izidov enaka: p*p*(1–p)*p = 0,1*0,1*0,9*0,1 = 0,0009. Če morate izračunati število izbir X n elementov, morate uporabiti kombinacijo formule (1):

kje n! = n * (n –1) * (n – 2) * … * 2 * 1 - faktoriel števila n, in 0! = 1 in 1! = 1 po definiciji.
Ta izraz se pogosto imenuje . Če je torej n = 4 in X = 3, je število zaporedij, sestavljenih iz treh elementov, ekstrahiranih iz velikosti vzorca 4, določeno z naslednjo formulo:
Zato se verjetnost odkrivanja treh napačnih naročil izračuna na naslednji način:
(Število možnih zaporedij) *
(verjetnost določenega zaporedja) = 4 * 0,0009 = 0,0036
Podobno lahko izračunate verjetnost, da bo med štirimi naročili eno ali dve napačni, pa tudi verjetnost, da so vsa naročila napačna ali vsa pravilna. Vendar z naraščajočo velikostjo vzorca n določanje verjetnosti določenega zaporedja izidov postane težje. V tem primeru bi morali uporabiti ustrezen matematični model, ki opisuje binomsko porazdelitev števila izbir X predmetov iz izbora, ki vsebuje n elementi.

skupaj izvedenih P(X)- verjetnost X uspeh za določeno velikost vzorca n in verjetnost uspeha r, X = 0, 1, … n.
Upoštevajte, da je formula (2) formalizacija intuitivnih zaključkov. Naključna spremenljivka X, ki upošteva binomsko porazdelitev, lahko sprejme poljubno celo število v območju od 0 do n. delo rX(1 – p)n – X predstavlja verjetnost določenega zaporedja, sestavljenega iz X uspeh v velikosti vzorca, ki je enak n. Vrednost določa število možnih kombinacij, sestavljenih iz X uspeh v n testi. Zato za določeno število testov n in verjetnost uspeha r verjetnost zaporedja, sestavljenega iz X uspeh, enak
P(X) = (število možnih zaporedij) * (verjetnost določenega zaporedja) = 
Oglejmo si primere, ki ponazarjajo uporabo formule (2).
1. Predpostavimo, da je verjetnost nepravilnega izpolnjevanja obrazca 0,1. Kakšna je verjetnost, da bodo med štirimi izpolnjenimi obrazci trije nepravilni? S formulo (2) ugotovimo, da je verjetnost odkrivanja treh napačnih naročil v vzorcu, sestavljenem iz štirih naročil, enaka
2. Predpostavimo, da je verjetnost nepravilnega izpolnjevanja obrazca 0,1. Kolikšna je verjetnost, da bodo med štirimi izpolnjenimi obrazci vsaj trije nepravilni? Kot je prikazano v prejšnjem primeru, je verjetnost, da bodo med štirimi izpolnjenimi obrazci trije nepravilni, 0,0036. Za izračun verjetnosti, da bodo med štirimi izpolnjenimi obrazci vsaj trije napačni, morate sešteti verjetnost, da bodo med štirimi izpolnjenimi obrazci trije napačni, in verjetnost, da bodo med štirimi izpolnjenimi obrazci vsi napačni. Verjetnost drugega dogodka je
Tako je verjetnost, da bodo med štirimi izpolnjenimi obrazci vsaj trije nepravilni, enaka
P(X > 3) = P(X = 3) + P(X = 4) = 0,0036 + 0,0001 = 0,0037
3. Predpostavimo, da je verjetnost nepravilnega izpolnjevanja obrazca 0,1. Kolikšna je verjetnost, da bodo od štirih izpolnjenih obrazcev manj kot trije nepravilni? Verjetnost tega dogodka
P(X< 3) = P(X = 0) + P(X = 1) + P(X = 2)
Z uporabo formule (2) izračunamo vsako od teh verjetnosti:

Zato je P(X< 3) = 0,6561 + 0,2916 + 0,0486 = 0,9963.
Verjetnost P(X< 3) можно вычислить иначе. Для этого воспользуемся тем, что событие X < 3 является дополнительным по отношению к событию Х>3. Potem P(X< 3) = 1 – Р(Х> 3) = 1 – 0,0037 = 0,9963.
Ko se velikost vzorca poveča n izračuni, podobni tistim v primeru 3, postanejo težavni. Da bi se izognili tem zapletom, je veliko binomskih verjetnosti tabeliranih vnaprej. Nekatere od teh verjetnosti so prikazane na sl. 1. Na primer, da bi dobili verjetnost, da X= 2 at n= 4 in str= 0,1, morate iz tabele izluščiti številko na presečišču črte X= 2 in stolpce r = 0,1.

riž. 1. Binomska verjetnost pri n = 4, X= 2 in r = 0,1
Binomsko porazdelitev je mogoče izračunati z uporabo Excelove funkcije=BINOM.DIST() (slika 2), ki ima 4 parametre: število uspehov – X, število testov (ali velikost vzorca) – n, verjetnost uspeha – r, parameter integral, ki ima vrednost TRUE (v tem primeru se izračuna verjetnost nič manj X dogodkov) ali FALSE (v tem primeru se izračuna verjetnost točno X dogodki).

riž. 2. Parametri funkcije =BINOM.DIST()
Za zgornje tri primere so izračuni prikazani na sl. 3 (glej tudi datoteko Excel). Vsak stolpec vsebuje eno formulo. Številke prikazujejo odgovore na primere ustreznega števila).

riž. 3. Izračun binomske porazdelitve v Excelu za n= 4 in str = 0,1
Lastnosti binomske porazdelitve
Binomska porazdelitev je odvisna od parametrov n in r. Binomska porazdelitev je lahko simetrična ali asimetrična. Če je p = 0,05, je binomska porazdelitev simetrična ne glede na vrednost parametra n. Če pa je p ≠ 0,05, postane porazdelitev poševna. Bližje kot je vrednost parametra r do 0,05 in čim večja je velikost vzorca n, manj izrazita je asimetrija porazdelitve. Tako je porazdelitev števila nepravilno izpolnjenih obrazcev nagnjena v desno, ker str= 0,1 (slika 4).

riž. 4. Histogram binomske porazdelitve pri n= 4 in str = 0,1
Pričakovanje binomske porazdelitve enak zmnožku velikosti vzorca n o verjetnosti uspeha r:
(3) M = E(X) =n.p.
V povprečju je lahko pri dovolj dolgem nizu testov v vzorcu, sestavljenem iz štirih nalogov, p = E(X) = 4 x 0,1 = 0,4 napačno izpolnjenih obrazcev.
Standardni odklon binomske porazdelitve
na primer standardni odklonštevilo nepravilno izpolnjenih obrazcev v računovodstvu informacijski sistem je enako:
Uporabljeno je gradivo iz knjige Levin et al. – M.: Williams, 2004. – str. 307–313


