Бинарный закон распределения. Биномиальный закон распределения
Теория вероятности незримо присутствует в нашей жизни. Мы не обращаем на это внимания, но каждое событие в нашей жизни имеет ту или иную вероятность. Принимая во внимание огромное количество вариантов развития событий, нам становится необходимым определять наиболее вероятные и наименее вероятные из них. Наиболее удобно анализировать такие вероятностные данные графически. В этом нам может помочь распределение. Биномиальное - одно из самых лёгких и самых точных.
Прежде чем перейти непосредственно к математике и теории вероятности, разберёмся с тем, кто же первый придумал такой вид распределения и какова история развития математического аппарата для этого понятия.
История
Понятие вероятности известно ещё с древних времён. Однако древние математики не придавали ей особо значения и смогли заложить только основы для теории, ставшей впоследствии теорией вероятности. Они создали некоторые комбинаторные методы, которые сильно помогли тем, кто позже создал и развил саму теорию.
Во второй половине семнадцатого века началось формирование основных понятий и методов теории вероятности. Были введены определения случайных величин, способы вычисления вероятности простых и некоторых сложных независимых и зависимых событий. Продиктован такой интерес к случайным величинам и вероятностям был азартными играми: каждый человек хотел знать, какие у него шансы победить в игре.
Следующим этапом стало применение в теории вероятности методов математического анализа. Этим занялись видные математики, такие как Лаплас, Гаусс, Пуассон и Бернулли. Именно они продвинули эту область математики на новый уровень. Именно Джеймс Бернулли открыл биномиальный закон распределения. Кстати, как мы позже выясним, на основе этого открытия были сделаны ещё несколько, которые позволили создать закон нормального распределения и ещё множество других.
Сейчас, прежде чем начать описывать распределение биномиальное, мы немного освежим в памяти понятия теории вероятностей, наверняка уже забытые со школьной скамьи.
Основы теории вероятностей
Будем рассматривать такие системы, в результате действия которых возможны только два исхода: "успех" и "не успех". Это легко понять на примере: мы подбрасываем монетку, загадав то, что выпадет решка. Вероятности каждого из возможных событий (выпадет решка - "успех", выпадет орёл - "не успех") равны 50 процентам при идеальной балансировке монеты и отсутствии прочих факторов, которые могут повлиять на эксперимент.
Это было самое простое событие. Но бывают ещё и сложные системы, в которых выполняются последовательные действия, и вероятности исходов этих действий будут различаться. Например, рассмотрим такую систему: в коробке, содержимое которой мы не можем разглядеть, лежат шесть абсолютно одинаковых шариков, три пары синего, красного и белого цветов. Мы должны достать наугад несколько шариков. Соответственно, вытащив первым один из белых шариков, мы уменьшим в разы вероятность того, что следующим нам тоже попадётся белый шарик. Происходит это потому, что меняется количество объектов в системе.
В следующем разделе рассмотрим более сложные математические понятия, вплотную подводящие нас к тому, что означают слова "нормальное распределение", "биномиальное распределение" и тому подобные.

Элементы математической статистики
В статистике, которая является одной из областей применения теории вероятностей, существует множество примеров, когда данные для анализа даны не в явном виде. То есть не в численном, а в виде разделения по признакам, например, по половым. Для того чтобы применить к таким данным математический аппарат и сделать из полученных результатов какие-то выводы, требуется перевести исходные данные в числовой формат. Как правило, для осуществления этого положительному исходу присваивают значение 1, а отрицательному - 0. Таким образом, мы получаем статистические данные, которые можно подвергнуть анализу с помощью математических методов.
Следующий шаг в понимании того, что такое биномиальное распределение случайной величины, - это определение дисперсии случайной величины и математического ожидания. Об этом поговорим в следующем разделе.

Математическое ожидание
На самом деле понять то, что такое математическое ожидание, несложно. Рассмотрим систему, в которой существует много разных событий со своими различными вероятностями. Математическим ожиданием будет называться величина, равная сумме произведений значений этих событий (а математическом виде, о котором мы говорили в прошлом разделе) на вероятности их осуществления.
Математическое ожидание биномиального распределения рассчитывается по той же самой схеме: мы берём значение случайной величины, умножаем его на вероятность положительного исхода, а затем суммируем полученные данные для всех величин. Очень удобно представить эти данные графически - так лучше воспринимается разница между математическими ожиданиями разных величин.
В следующем разделе мы расскажем вам немного о другом понятии - дисперсии случайной величины. Оно тоже тесно связано с таким понятием, как биномиальное распределение вероятностей, и является его характеристикой.

Дисперсия биномиального распределения
Эта величина тесно связана с предыдущей и также характеризует распределение статистических данных. Она представляет собой средний квадрат отклонений значений от их математического ожидания. То есть дисперсия случайной величины - это сумма квадратов разностей между значением случайной величины и её математическим ожиданием, умноженная на вероятность этого события.
В общем, это всё, что нам нужно знать о дисперсии для понимания того, что такое биномиальное распределение вероятностей. Теперь перейдём непосредственно к нашей основной теме. А именно к тому, что же кроется за таким на вид достаточно сложным словосочетанием "биномиальный закон распределения".

Биномиальное распределение
Разберёмся для начала, почему же это распределение биномиальное. Оно происходит от слова "бином". Может быть, вы слышали о биноме Ньютона - такой формуле, с помощью которой можно разложить сумму двух любых чисел a и b в любой неотрицательной степени n.
Как вы, наверное, уже догадались, формула бинома Ньютона и формула биномиального распределения - это практически одинаковые формулы. За тем лишь исключением, что вторая имеет прикладное значение для конкретных величин, а первая - лишь общий математический инструмент, применения которого на практике могут быть различны.
Формулы распределения
Функция биномиального распределения может быть записана в виде суммы следующих членов:
(n!/(n-k)!k!)*p k *q n-k
Здесь n - число независимых случайных экспериментов, p- число удачных исходов, q- число неудачных исходов, k - номер эксперимента (может принимать значения от 0 до n),! - обозначение факториала, такой функции числа, значение которой равно произведению всех идущих до неё чисел (например, для числа 4: 4!=1*2*3*4=24).
Помимо этого, функция биномиального распределения может быть записана в виде неполной бета-функции. Однако это уже более сложное определение, которое используется только при решении сложных статистических задач.
Биномиальное распределение, примеры которого мы рассмотрели выше, - одно из самых простых видов распределений в теории вероятностей. Существует также нормальное распределение, являющееся одним из видов биномиального. Оно используется чаще всего, и наиболее просто в расчётах. Бывает также распределение Бернулли, распределение Пуассона, условное распределение. Все они характеризуют графически области вероятности того или иного процесса при разных условиях.
В следующем разделе рассмотрим аспекты, касающиеся применения этого математического аппарата в реальной жизни. На первый взгляд, конечно, кажется, что это очередная математическая штука, которая, как обычно, не находит применения в реальной жизни, и вообще не нужна никому, кроме самих математиков. Однако это далеко не так. Ведь все виды распределений и их графические представления были созданы исключительно под практические цели, а не в качестве прихоти учёных.

Применение
Безусловно, самое важное применение распределения находят в статистике, ведь там нужен комплексный анализ множества данных. Как показывает практика, очень многие массивы данных имеют примерно одинаковые распределения величин: критические области очень низких и очень высоких величин, как правило, содержат меньше элементов, чем средние значения.
Анализ больших массивов данных требуется не только в статистике. Он незаменим, например, в физической химии. В этой науке он используется для определения многих величин, которые связаны со случайными колебаниями и перемещениями атомов и молекул.
В следующем разделе разберёмся, насколько важно применение таких статистических понятий, как биномиальное распределение случайной величины в повседневной жизни для нас с вами.

Зачем мне это нужно?
Многие задают себе такой вопрос, когда дело касается математики. А между прочим, математика не зря называется царицей наук. Она является основой физики, химии, биологии, экономики, и в каждой из этих наук применяется в том числе и какое-либо распределение: будь это дискретное биномиальное распределение, или же нормальное, не важно. И если мы получше присмотримся к окружающему миру, то увидим, что математика применяется везде: в повседневной жизни, на работе, да даже человеческие отношения можно представить в виде статистических данных и провести их анализ (так, кстати, и делают те, кто работают в специальных организациях, занимающихся сбором информации).
Сейчас поговорим немного о том, что же делать, если вам нужно знать по данной теме намного больше, чем то, что мы изложили в этой статье.
Та информация, что мы дали в этой статье, далеко не полная. Существует множество нюансов, касаемо того, какую форму может принимать распределение. Биномиальное распределение, как мы уже выяснили, является одним из основных видов, на котором зиждется вся математическая статистика и теория вероятностей.
Если вам стало интересно, или в связи с вашей работой вам нужно знать по этой теме гораздо больше, нужно будет изучить специализированную литературу. Начать следует с университетского курса математического анализа и дойти там до раздела теории вероятностей. Также пригодятся знания в области рядов, ведь биномиальное распределение вероятностей - это ни что иное, как ряд последовательных членов.
Заключение
Прежде чем закончить статью, мы хотели бы рассказать ещё одну интересную вещь. Она касается непосредственно темы нашей статьи и всей математики в целом.
Многие люди твердят, что математика - бесполезная наука, и ничто из того, что они проходили в школе, им не пригодилось. Но знание ведь никогда не бывает лишним, и если вам что-то не пригодилось в жизни, значит, вы просто этого не помните. Если у вас есть знания, они могут вам помочь, но если их нет, то и помощи от них ждать не приходится.
Итак, мы рассмотрели понятие биномиального распределения и все связанные с ним определения и поговорили о том, как же это применяется в нашей с вами жизни.
Биномиальное распределение
распределение вероятностей числа появлений некоторого события при повторных независимых испытаниях. Если при каждом испытании вероятность появления события равна р,
причём 0 ≤ p
≤ 1, то число μ появлений этого события при n
независимых испытаниях есть случайная величина, принимающая значения m
= 1, 2,.., n
с вероятностями где q
= 1 - p,
a Лит.:
Большев Л. Н., Смирнов Н. В., Таблицы математической статистики, М., 1965.![]() -
биномиальные коэффициенты (отсюда название Б. р.). Приведённая формула иногда называется формулой Бернулли. Математическое ожидание и Дисперсия величины μ, имеющей Б. р., равны М
(μ) = np
и D
(μ) = npq
, соответственно. При больших n,
в силу Лапласа теоремы (См. Лапласа теорема), Б. р. близко к нормальному распределению (См. Нормальное распределение), чем и пользуются на практике. При небольших n
приходится пользоваться таблицами Б. р.
-
биномиальные коэффициенты (отсюда название Б. р.). Приведённая формула иногда называется формулой Бернулли. Математическое ожидание и Дисперсия величины μ, имеющей Б. р., равны М
(μ) = np
и D
(μ) = npq
, соответственно. При больших n,
в силу Лапласа теоремы (См. Лапласа теорема), Б. р. близко к нормальному распределению (См. Нормальное распределение), чем и пользуются на практике. При небольших n
приходится пользоваться таблицами Б. р.
Большая советская энциклопедия. - М.: Советская энциклопедия . 1969-1978 .
Смотреть что такое "Биномиальное распределение" в других словарях:
Функция вероятности … Википедия
- (binomial distribution) Распределение, позволяющее рассчитать вероятность наступления какого либо случайного события, полученного в результате наблюдений ряда независимых событий, если вероятность наступления, составляющих его элементарных… … Экономический словарь
- (распределение Бернулли) распределение вероятностей числа появлений некоторого события при повторных независимых испытаниях, если вероятность появления этого события в каждом испытании равна p(0 p 1). Именно, число? появлений этого события есть… … Большой Энциклопедический словарь
биномиальное распределение - — Тематики электросвязь, основные понятия EN binomial distribution …
- (распределение Бернулли), распределение вероятностей числа появлений некоторого события при повторных независимых испытаниях, если вероятность появления этого события в каждом испытании равна р (0≤р≤1). Именно, число μ появлений этого события… … Энциклопедический словарь
биномиальное распределение - 1.49. биномиальное распределение Распределение вероятностей дискретной случайной величины X, принимающей любые целые значения от 0 до n, такое что при х = 0, 1, 2, ..., n и параметрах n = 1, 2, ... и 0 < p < 1, где Источник … Словарь-справочник терминов нормативно-технической документации
Распределение Бернулли, распределение вероятностей случайной величины X, принимающей целочисленные значения с вероятностями соответственно (биномиальный коэффициент; р параметр Б. р., наз. вероятностью положительного исхода, принимающей значения … Математическая энциклопедия
- (распределение Бернулли), распределение вероятностей числа появлений нек рого события при повторных независимых испытаниях, если вероятность появления этого события в каждом испытании равна р (0<или = p < или = 1). Именно, число м появлений … Естествознание. Энциклопедический словарь
Биномиальное распределение вероятностей - (binomial distribution) Распределение, которое наблюдается в случаях, когда исход каждого независимого эксперимента (статистического наблюдения) принимает одно из двух возможных значений: победа или поражение, включение или исключение, плюс или … Экономико-математический словарь
биномиальное распределение вероятностей - Распределение, которое наблюдается в случаях, когда исход каждого независимого эксперимента (статистического наблюдения) принимает одно из двух возможных значений: победа или поражение, включение или исключение, плюс или минус, 0 или 1. То есть… … Справочник технического переводчика
Книги
- Теория вероятностей и математическая статистика в задачах. Более 360 задач и упражнений , Д. А. Борзых. В предлагаемом пособии содержатся задачи различного уровня сложности. Однако основной акцент сделан на задачах средней сложности. Это сделано намеренно с тем, чтобы побудить студентов к…
- Теория вероятностей и математическая статистика в задачах: Более 360 задач и упражнений , Борзых Д.. В предлагаемом пособии содержатся задачи различного уровня сложности. Однако основной акцент сделан на задачах средней сложности. Это сделано намеренно с тем, чтобы побудить студентов к…
Рассмотрим Биномиальное распределение, вычислим его математическое ожидание, дисперсию, моду. С помощью функции MS EXCEL БИНОМ.РАСП() построим графики функции распределения и плотности вероятности. Произведем оценку параметра распределения p, математического ожидания распределения и стандартного отклонения. Также рассмотрим распределение Бернулли.
Определение . Пусть проводятся n испытаний, в каждом из которых может произойти только 2 события: событие «успех» с вероятностью p или событие «неудача» с вероятностью q =1-p (так называемая Схема Бернулли, Bernoulli trials ).
Вероятность получения ровно x успехов в этих n испытаниях равна:
Количество успехов в выборке x является случайной величиной, которая имеет Биномиальное распределение (англ. Binomial distribution ) p и n – являются параметрами этого распределения.
Напомним, что для применения схемы Бернулли и соответственно Биномиального распределения, должны быть выполнены следующие условия:
- каждое испытание должно иметь ровно два исхода, условно называемых «успехом» и «неудачей».
- результат каждого испытания не должен зависеть от результатов предыдущих испытаний (независимость испытаний).
- вероятность успеха p должна быть постоянной для всех испытаний.
Биномиальное распределение в MS EXCEL
В MS EXCEL, начиная с версии 2010, для Биномиального распределения имеется функция БИНОМ.РАСП() , английское название - BINOM.DIST(), которая позволяет вычислить вероятность того, что в выборке будет ровно х «успехов» (т.е. функцию плотности вероятности p(x), см. формулу выше), и интегральную функцию распределения (вероятность того, что в выборке будет x или меньше «успехов», включая 0).
До MS EXCEL 2010 в EXCEL была функция БИНОМРАСП() , которая также позволяет вычислить функцию распределения и плотность вероятности p(x). БИНОМРАСП() оставлена в MS EXCEL 2010 для совместимости.
В файле примера приведены графики плотности распределения вероятности и .

Биномиальное распределения имеет обозначение B (n ; p ) .
Примечание : Для построения интегральной функции распределения идеально подходит диаграмма типа График , для плотности распределения – Гистограмма с группировкой . Подробнее о построении диаграмм читайте статью Основные типы диаграмм.
Примечание : Для удобства написания формул в файле примера созданы Имена для параметров Биномиального распределения : n и p.

В файле примера приведены различные расчеты вероятности с помощью функций MS EXCEL:

Как видно на картинке выше, предполагается, что:
- В бесконечной совокупности, из которой делается выборка, содержится 10% (или 0,1) годных элементов (параметр p , третий аргумент функции =БИНОМ.РАСП() )
- Чтобы вычислить вероятность, того что в выборке из 10 элементов (параметр n , второй аргумент функции) будет ровно 5 годных элементов (первый аргумент), нужно записать формулу: =БИНОМ.РАСП(5; 10; 0,1; ЛОЖЬ)
- Последний, четвертый элемент, установлен =ЛОЖЬ, т.е. возвращается значение функции плотности распределения .
Если значение четвертого аргумента =ИСТИНА, то функция БИНОМ.РАСП() возвращает значение интегральной функции распределения или просто Функцию распределения . В этом случае можно рассчитать вероятность того, что в выборке количество годных элементов будет из определенного диапазона, например, 2 или меньше (включая 0).
Для этого нужно записать формулу:
= БИНОМ.РАСП(2; 10; 0,1; ИСТИНА)
Примечание
: При нецелом значении х, . Например, следующие формулы вернут одно и тоже значение:
=БИНОМ.РАСП(2
; 10; 0,1; ИСТИНА)
=БИНОМ.РАСП(2,9
; 10; 0,1; ИСТИНА)
Примечание : В файле примера плотность вероятности и функция распределения также вычислены с использованием определения и функции ЧИСЛКОМБ() .
Показатели распределения
В файле примера на листе Пример имеются формулы для расчета некоторых показателей распределения:
- =n*p;
- (квадрата стандартного отклонения) = n*p*(1-p);
- = (n+1)*p;
- =(1-2*p)*КОРЕНЬ(n*p*(1-p)).
Выведем формулу математического ожидания Биномиального распределения , используя Схему Бернулли .
По определению случайная величина Х в схеме Бернулли (Bernoulli random variable) имеет функцию распределения :

Это распределение называется распределение Бернулли .
Примечание : распределение Бернулли – частный случай Биномиального распределения с параметром n=1.
Сгенерируем 3 массива по 100 чисел с различными вероятностями успеха: 0,1; 0,5 и 0,9. Для этого в окне Генерация случайных чисел установим следующие параметры для каждой вероятности p:

Примечание : Если установить опцию Случайное рассеивание (Random Seed ), то можно выбрать определенный случайный набор сгенерированных чисел. Например, установив эту опцию =25 можно сгенерировать на разных компьютерах одни и те же наборы случайных чисел (если, конечно, другие параметры распределения совпадают). Значение опции может принимать целые значения от 1 до 32 767. Название опции Случайное рассеивание может запутать. Лучше было бы ее перевести как Номер набора со случайными числами .
В итоге будем иметь 3 столбца по 100 чисел, на основании которых можно, например, оценить вероятность успеха p по формуле: Число успехов/100 (см. файл примера лист ГенерацияБернулли ).
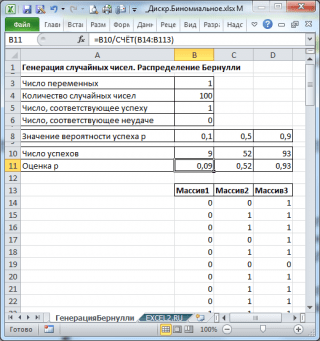
Примечание : Для распределения Бернулли с p=0,5 можно использовать формулу =СЛУЧМЕЖДУ(0;1) , которая соответствует .
Генерация случайных чисел. Биномиальное распределение
Предположим, что в выборке обнаружилось 7 дефектных изделий. Это означает, что «очень вероятна» ситуация, что изменилась доля дефектных изделий p , которая является характеристикой нашего производственного процесса. Хотя такая ситуация «очень вероятна», но существует вероятность (альфа-риск, ошибка 1-го рода, «ложная тревога»), что все же p осталась без изменений, а увеличенное количество дефектных изделий обусловлено случайностью выборки.
Как видно на рисунке ниже, 7 – количество дефектных изделий, которое допустимо для процесса с p=0,21 при том же значении Альфа . Это служит иллюстрацией, что при превышении порогового значения дефектных изделий в выборке, p «скорее всего» увеличилось. Фраза «скорее всего» означает, что существует всего лишь 10% вероятность (100%-90%) того, что отклонение доли дефектных изделий выше порогового вызвано только сучайными причинами.

Таким образом, превышение порогового количества дефектных изделий в выборке, может служить сигналом, что процесс расстроился и стал выпускать бо льший процент бракованных изделий.
Примечание : До MS EXCEL 2010 в EXCEL была функция КРИТБИНОМ() , которая эквивалентна БИНОМ.ОБР() . КРИТБИНОМ() оставлена в MS EXCEL 2010 и выше для совместимости.
Связь Биномиального распределения с другими распределениями
Если параметр n
Биномиального распределения
стремится к бесконечности, а p
стремится к 0, то в этом случае Биномиальное распределение
может быть аппроксимировано .
Можно сформулировать условия, когда приближение распределением Пуассона
работает хорошо:
- p <0,1 (чем меньше p и больше n , тем приближение точнее);
- p >0,9 (учитывая, что q =1- p , вычисления в этом случае необходимо производить через q (а х нужно заменить на n - x ). Следовательно, чем меньше q и больше n , тем приближение точнее).
При 0,1<=p<=0,9 и n*p>10 Биномиальное распределение можно аппроксимировать .
В свою очередь, Биномиальное распределение может служить хорошим приближением , когда размер совокупности N Гипергеометрического распределения гораздо больше размера выборки n (т.е., N>>n или n/N<<1).
Подробнее о связи вышеуказанных распределений, можно прочитать в статье . Там же приведены примеры аппроксимации, и пояснены условия, когда она возможна и с какой точностью.
СОВЕТ : О других распределениях MS EXCEL можно прочитать в статье .
Распределения вероятностей дискретных случайных величин. Биномиальное распределение. Распределение Пуассона. Геометрическое распределение. Производящая функция.
6. Распределения вероятностей дискретных случайных величин
6.1. Биномиальное распределение
Пусть производится n независимых испытаний, в каждом из которых событие A может либо появится, либо не появится. Вероятность p появления события A во всех испытаниях постоянна и не изменяется от испытания к испытанию. Рассмотрим в качестве случайной величины X число появлений события A в этих испытаниях. Формула, позволяющая найти вероятность появления события A ровно k раз в n испытаниях, как известно, описывается формулой Бернулли
Распределение вероятностей, определяемое формулой Бернулли, называется биномиальным .
Этот закон назван "биномиальным" потому, что правую часть можно рассматривать как общий член разложения бинома Ньютона
Запишем биномиальный закон в виде таблицы
|
p n |
np n –1 q |
|
q n |

Найдем числовые характеристики этого распределения.
По определению математического ожидания для ДСВ имеем
 .
.
Запишем равенство, являющееся бином Ньютона
 .
.
и продифференцируем его по p. В результате получим
 .
.
Умножим левую и правую часть на p :
 .
.
Учитывая, что p + q =1, имеем
 (6.2)
(6.2)
Итак, математическое ожидание числа появлений событий в n независимых испытаниях равно произведению числа испытаний n на вероятность p появления события в каждом испытании .
Дисперсию вычислим по формуле
 .
.
Для этого найдем
 .
.
Предварительно продифференцируем формулу бинома Ньютона два раза по p :

и умножим обе части равенства на p 2:

Следовательно,
Итак, дисперсия биномиального распределения равна
 .
(6.3)
.
(6.3)
Данные результаты можно получить и из чисто качественных рассуждений. Общее число X появлений события A во всех испытаниях складываются из числа появлений события в отдельных испытаниях. Поэтому если X 1 – число появлений события в первом испытании, X 2 – во втором и т.д., то общее число появлений события A во всех испытаниях равно X=X 1 +X 2 +…+X n . По свойству математического ожидания:
Каждое из слагаемых правой части равенства есть математическое ожидание числа событий в одном испытании, которое равно вероятности события. Таким образом,
По свойству дисперсии:
Так
как
,
а математическое ожидание случайной
величины ,
которое может принимать только два
значения, а именно 1 2
с вероятностью p
и 0 2
с вероятностью q
,
то
,
которое может принимать только два
значения, а именно 1 2
с вероятностью p
и 0 2
с вероятностью q
,
то
 .
Таким образом,
.
Таким образом, В результате, получаем
В результате, получаем
Воспользовавшись понятием начальных и центральных моментов, можно получить формулы для асимметрии и эксцесса:
 .
(6.4)
.
(6.4)

Рис. 6.1
Многоугольник биномиального распределения имеет следующий вид (см. рис. 6.1). ВероятностьP n (k ) сначала возрастает при увеличении k , достигает наибольшего значения и далее начинает убывать. Биномиальное распределение асимметрично, за исключением случая p =0,5. Отметим, что при большом числе испытаний n биномиальное распределение весьма близко к нормальному. (Обоснование этого предложения связано с локальной теоремой Муавра-Лапласа.)Число m 0 наступлений события называется наивероятнейшим , если вероятность наступления события данное число раз в этой серии испытаний наибольшая (максимум в многоугольнике распределения) . Для биномиального распределения
Замечание. Данное неравенство можно доказать, используя рекуррентную формулу для биномиальных вероятностей:
 (6.6)
(6.6)
Пример 6.1. Доля изделий высшего сорта на данном предприятии составляет 31%. Чему равно математического ожидание и дисперсия, также наивероятнейшее число изделий высшего сорта в случайно отобранной партии из 75 изделий?
Решение. Поскольку p =0,31, q =0,69, n =75, то
M[X ] = np = 750,31 = 23,25; D[X ] = npq = 750,310,69 = 16,04.
Для нахождения наивероятнейшего числа m 0 , составим двойное неравенство
Отсюда следует, что m 0 = 23.
Конечно, при вычислении кумулятивной функции распределения следует воспользоваться упомянутой связью биномиального и бета- распределения. Этот способ заведомо лучше непосредственного суммирования, когда n > 10.
В классических учебниках по статистике для получения значений биномиального распределения часто рекомендуют использовать формулы, основанные на предельных теоремах (типа формулы Муавра-Лапласа). Необходимо отметить, что с чисто вычислительной точки зрения ценность этих теорем близка к нулю, особенно сейчас, когда практически на каждом столе стоит мощный компьютер. Основной недостаток приведенных аппроксимаций – их совершенно недостаточная точность при значениях n, характерных для большинства приложений. Не меньшим недостатком является и отсутствие сколько-нибудь четких рекомендаций о применимости той или иной аппроксимации (в стандартных текстах приводятся лишь асимптотические формулировки, они не сопровождаются оценками точности и, следовательно, мало полезны). Я бы сказал, что обе формулы пригодны лишь при n < 200 и для совсем грубых, ориентировочных расчетов, причем делаемых “вручную” с помощью статистических таблиц. А вот связь между биномиальным распределением и бета-распределением позволяет вычислять биномиальное распределение достаточно экономно.
Я не рассматриваю здесь задачу поиска квантилей: для дискретных распределений она тривиальна, а в тех задачах, где такие распределения возникают, она, как правило, и не актуальна. Если же квантили все-таки понадобятся, рекомендую так переформулировать задачу, чтобы работать с p-значениями (наблюденными значимостями). Вот пример: при реализации некоторых переборных алгоритмов на каждом шаге требуется проверять статистическую гипотезу о биномиальной случайной величине. Согласно классическому подходу на каждом шаге нужно вычислить статистику критерия и сравнить ее значение с границей критического множества. Поскольку, однако, алгоритм переборный, приходится определять границу критического множества каждый раз заново (ведь от шага к шагу объем выборки меняется), что непроизводительно увеличивает временные затраты. Современный подход рекомендует вычислять наблюденную значимость и сравнивать ее с доверительной вероятностью, экономя на поиске квантилей.
Поэтому в приводимых ниже кодах отсутствует вычисление обратной функции, взамен приведена функция rev_binomialDF , которая вычисляет вероятность p успеха в отдельном испытании по заданному количеству n испытаний, числу m успехов в них и значению y вероятности получить эти m успехов. При этом используется вышеупомянутая связь между биномиальным и бета распределениями.
Фактически, эта функция позволяет получать границы доверительных интервалов.
В самом деле, предположим, что в n
биномиальных испытаниях мы получили m
успехов. Как известно, левая граница двухстороннего доверительного интервала
для параметра p с доверительным уровнем
равна 0, если
m = 0, а для
является решением уравнения  .
Аналогично, правая граница равна 1,
если m = n, а для
является решением уравнения
.
Аналогично, правая граница равна 1,
если m = n, а для
является решением уравнения  .
Отсюда вытекает, что для поиска левой границы мы должны решать относительно
уравнение
.
Отсюда вытекает, что для поиска левой границы мы должны решать относительно
уравнение
 ,
а для поиска правой – уравнение
,
а для поиска правой – уравнение
 .
Они и решаются в функциях binom_leftCI и binom_rightCI ,
возвращающих верхнюю и нижнюю границы двустороннего доверительного интервала
соответственно.
.
Они и решаются в функциях binom_leftCI и binom_rightCI ,
возвращающих верхнюю и нижнюю границы двустороннего доверительного интервала
соответственно.
Хочу заметить, что если не нужна совсем уж неимоверная точность, то
при достаточно больших n можно воспользоваться
следующей аппроксимацией [Б.Л. ван дер Варден, Математическая статистика.
М: ИЛ, 1960, гл. 2, разд. 7]:
 ,
где g – квантиль нормального распределения.
Ценность этой аппроксимации в том, что имеются очень простые приближения,
позволяющие вычислять квантили нормального распределения (см. текст о вычислении
нормального распределения и соответствующий раздел данного справочника).
В моей практике (в основном, при n > 100) эта аппроксимация давала примерно 3-4 знака, чего, как правило,
вполне достаточно.
,
где g – квантиль нормального распределения.
Ценность этой аппроксимации в том, что имеются очень простые приближения,
позволяющие вычислять квантили нормального распределения (см. текст о вычислении
нормального распределения и соответствующий раздел данного справочника).
В моей практике (в основном, при n > 100) эта аппроксимация давала примерно 3-4 знака, чего, как правило,
вполне достаточно.
Для вычислений с помощью нижеследующих кодов потребуются файлы betaDF.h , betaDF.cpp (см. раздел о бета-распределении), а также logGamma.h , logGamma.cpp (см. приложение А). Вы можете посмотреть также пример использования функций.
Файл binomialDF.h
| #ifndef __BINOMIAL_H__ #include "betaDF.h" double binomialDF(double trials, double successes, double p); /* * Пусть имеется "trials" независимых наблюдений * с вероятностью "p" успеха в каждом. * Вычисляется вероятность B(successes|trials,p) того, что число * успехов заключено между 0 и "successes" (включительно). */ double rev_binomialDF(double trials, double successes, double y); /* * Пусть известна вероятность y наступления не менее m успехов * в trials испытаниях схемы Бернулли. Функция находит вероятность p * успеха в отдельном испытании. * * В вычислениях используется следующее соотношение * * 1 - p = rev_Beta(trials-successes| successes+1, y). */ double binom_leftCI(double trials, double successes, double level); /* Пусть имеется "trials" независимых наблюдений * с вероятностью "p" успеха в каждом * и количество успехов равно "successes". * Вычисляется левая граница двустороннего доверительного интервала * с уровнем значимости level. */ double binom_rightCI(double n, double successes, double level); /* Пусть имеется "trials" независимых наблюдений * с вероятностью "p" успеха в каждом * и количество успехов равно "successes". * Вычисляется правая граница двустороннего доверительного интервала * с уровнем значимости level. */ #endif /* Ends #ifndef __BINOMIAL_H__ */ |
Файл binomialDF.cpp
|
/***********************************************************/
/* Биномиальное распределение */
/***********************************************************/
#include |


